Michael Xieyang Liu
Senior Research Scientist
@GoogleDeepMind

Michael Xieyang Liu is a Senior Research Scientist at Google DeepMind in the PAIR (People + AI Research Initiative) team. His research aims to improve human-AI interaction, with a particular focus on human interaction with multimodal large language models and controllable AI.
He previously earned his Ph.D. from the Human-Computer Interaction Institute @ Carnegie Mellon University, where he was advised by Dr. Brad A. Myers and Dr. Niki Kittur. During his Ph.D., he interned at the RiSE group and Calc Intelligence group at Microsoft Research, the Google Cloud team at Google, and Bosch Research.
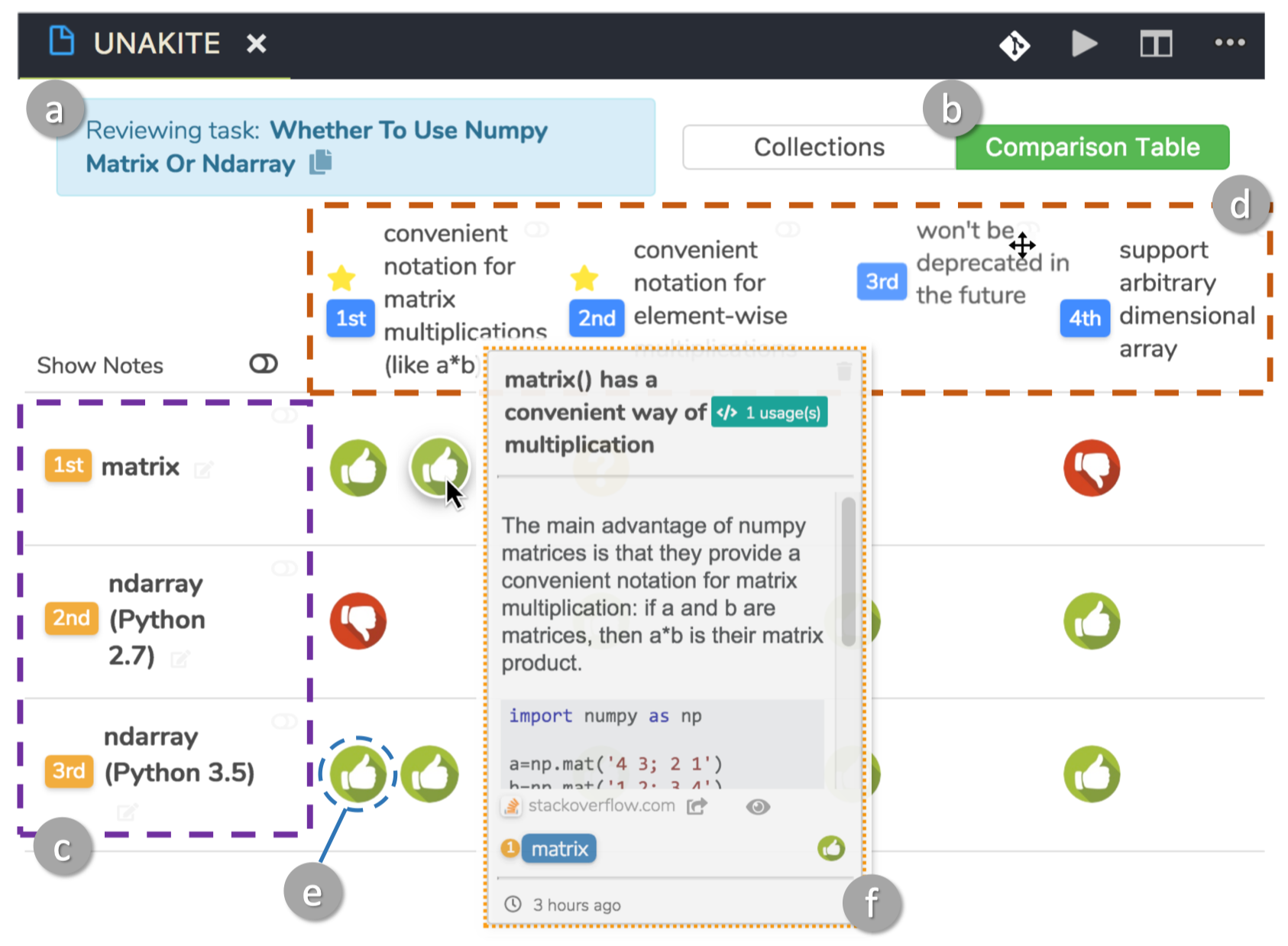
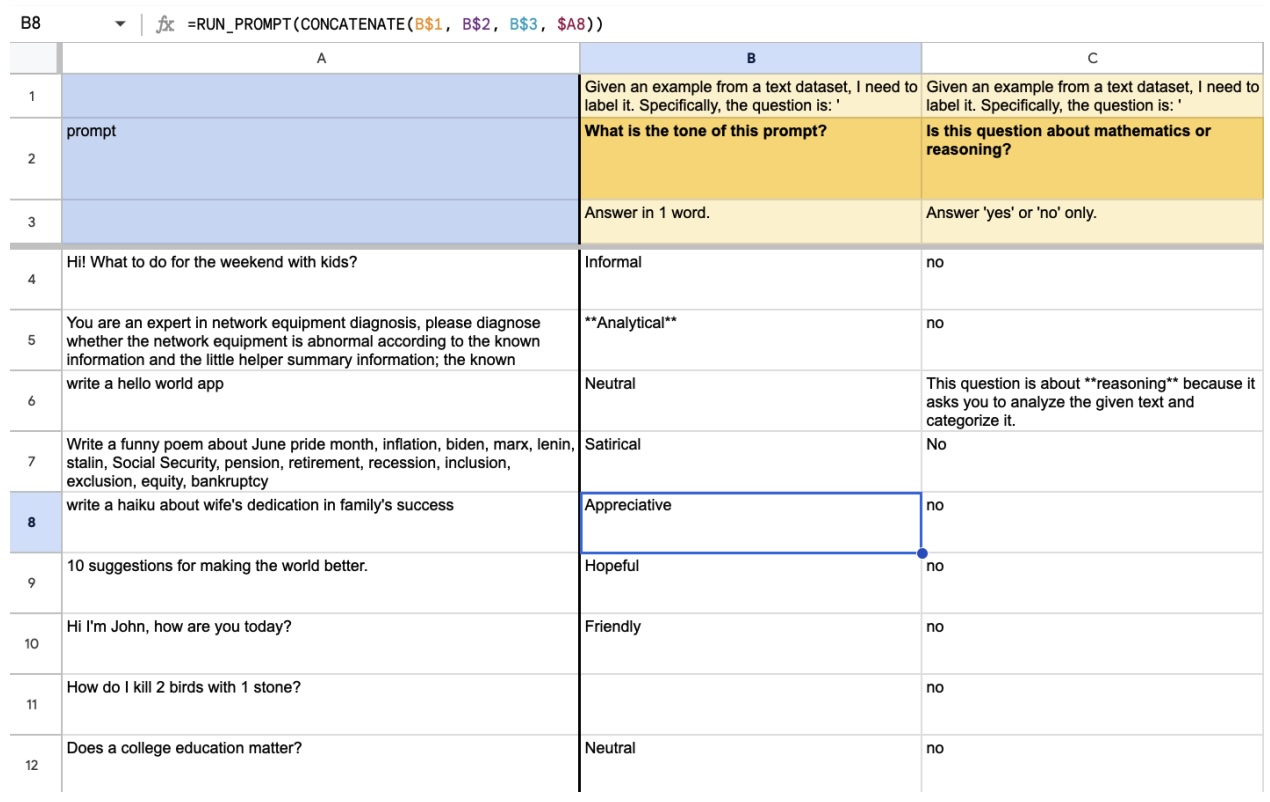
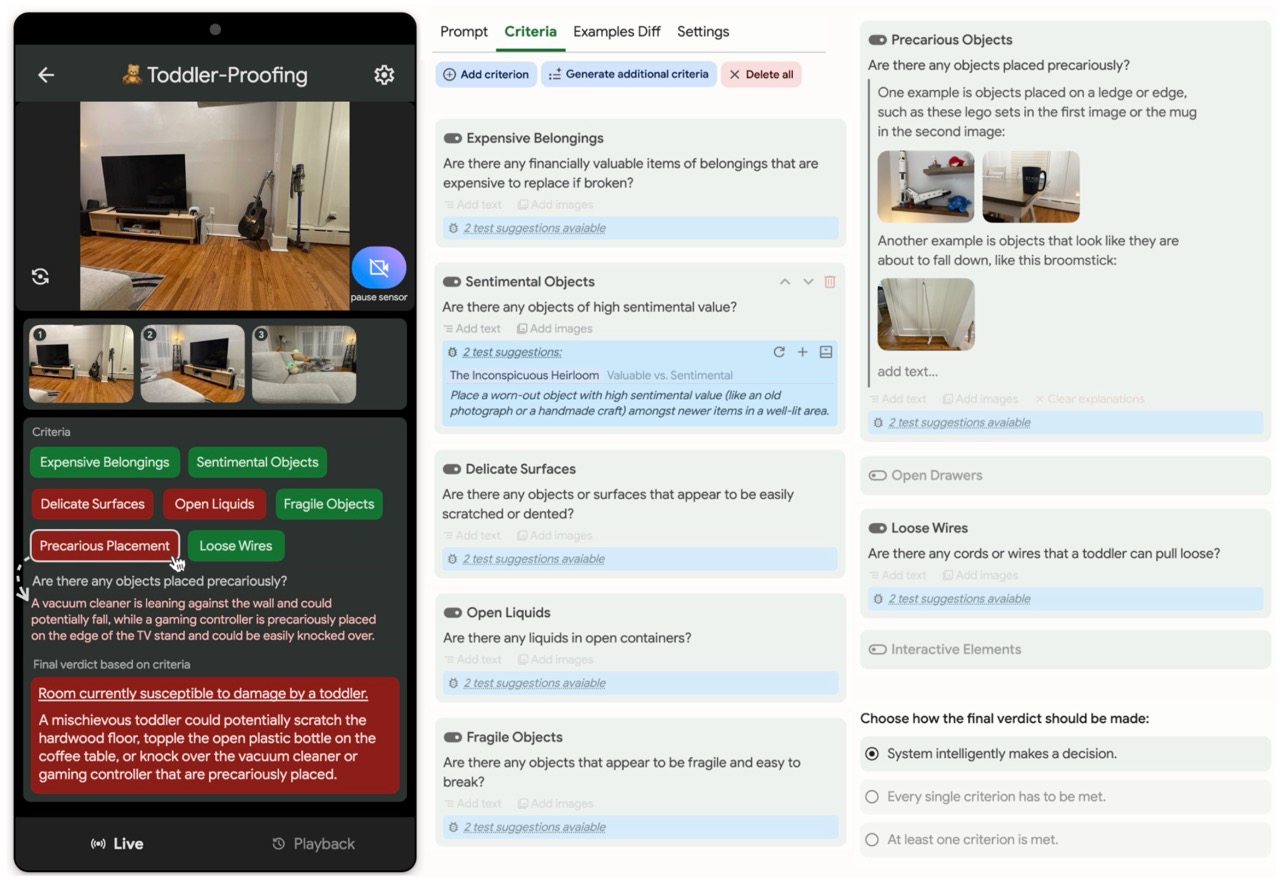
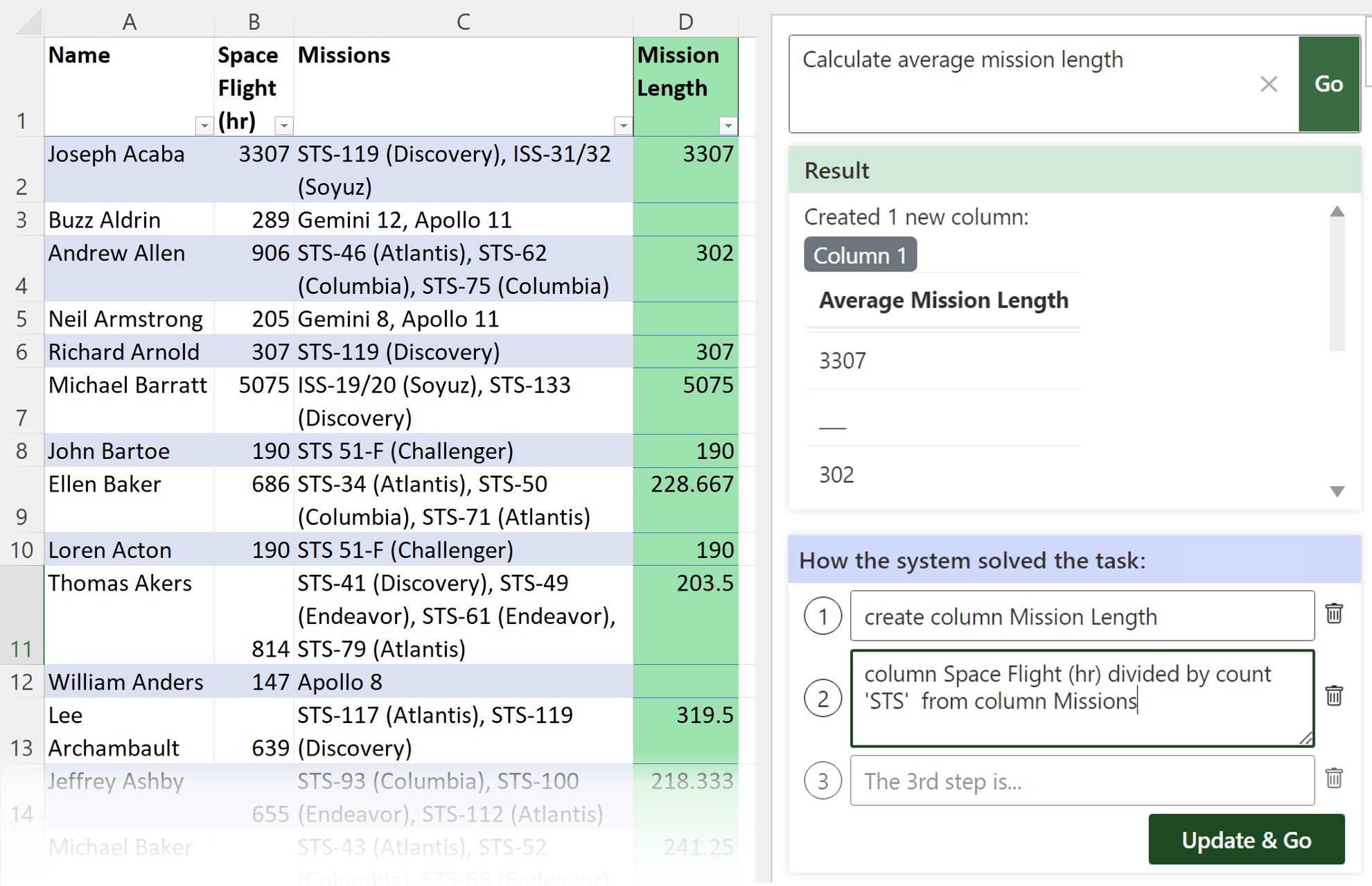
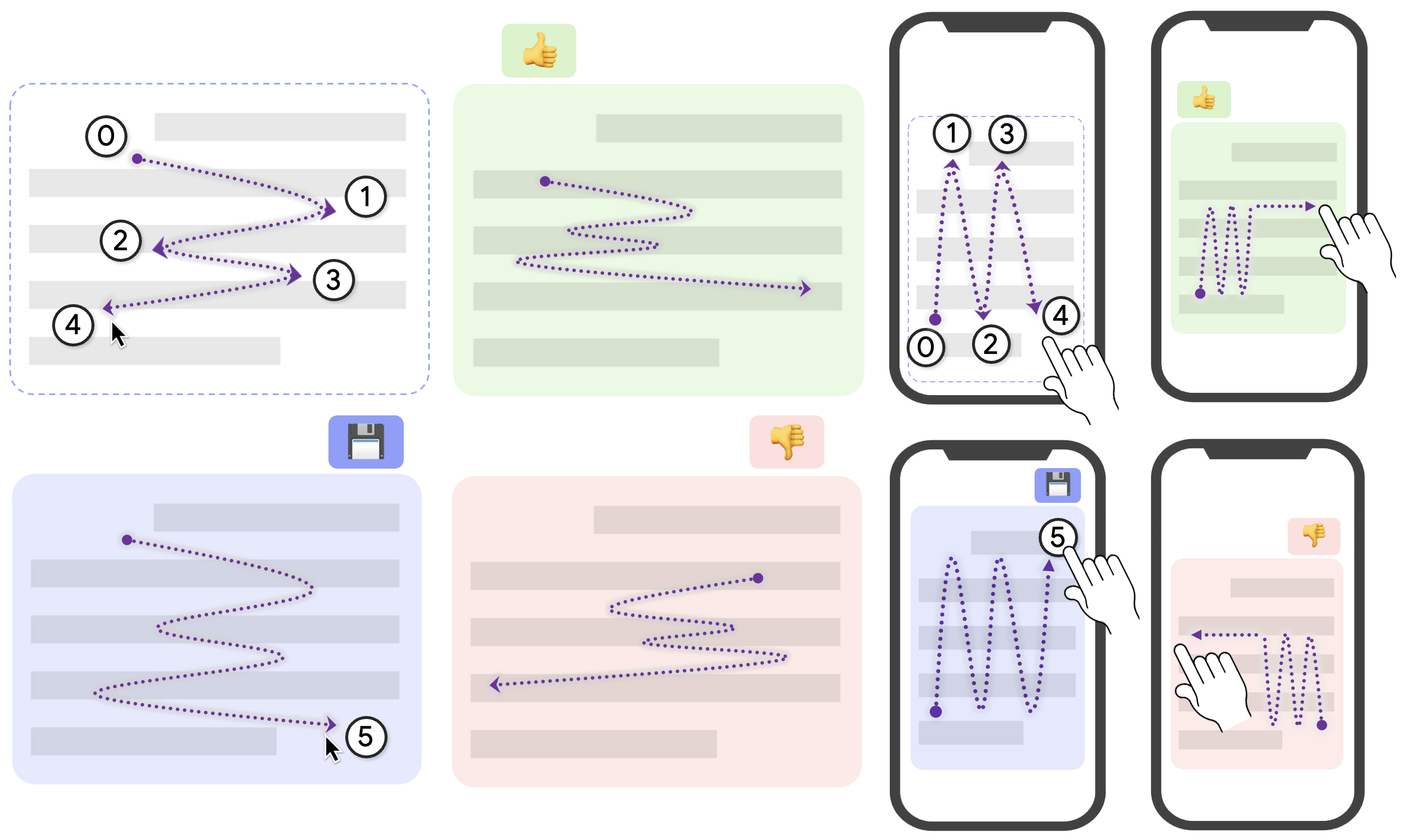
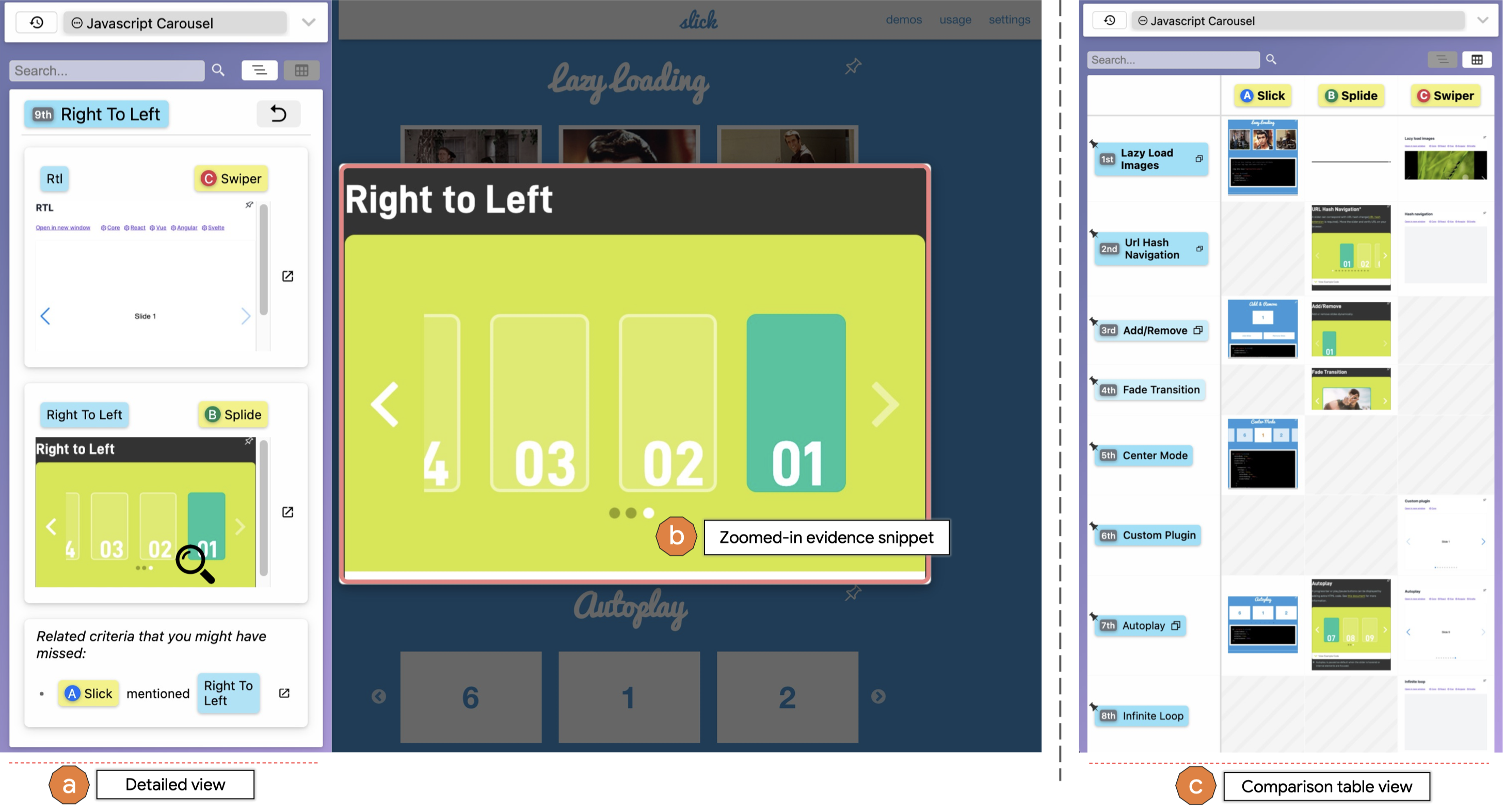
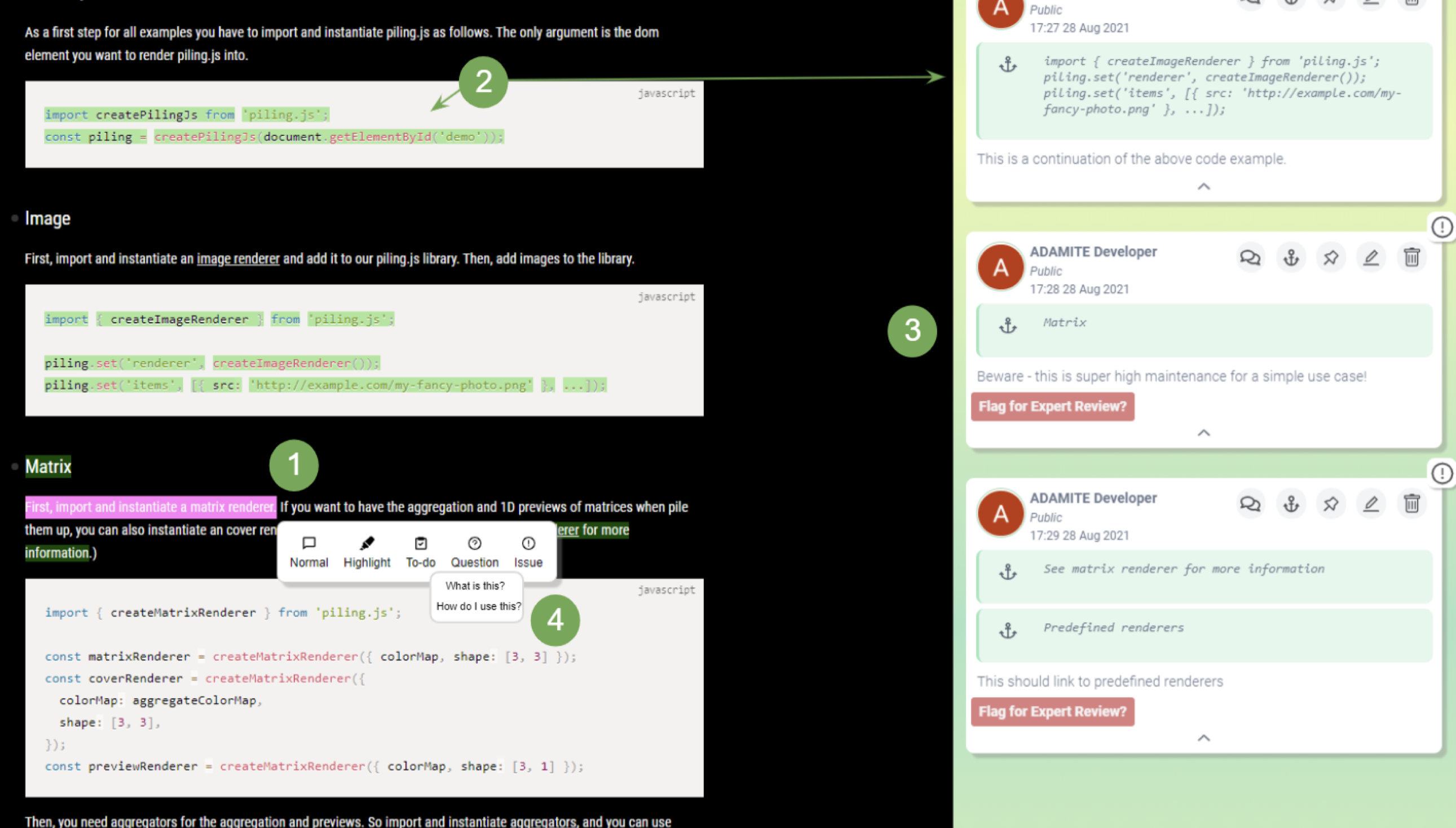
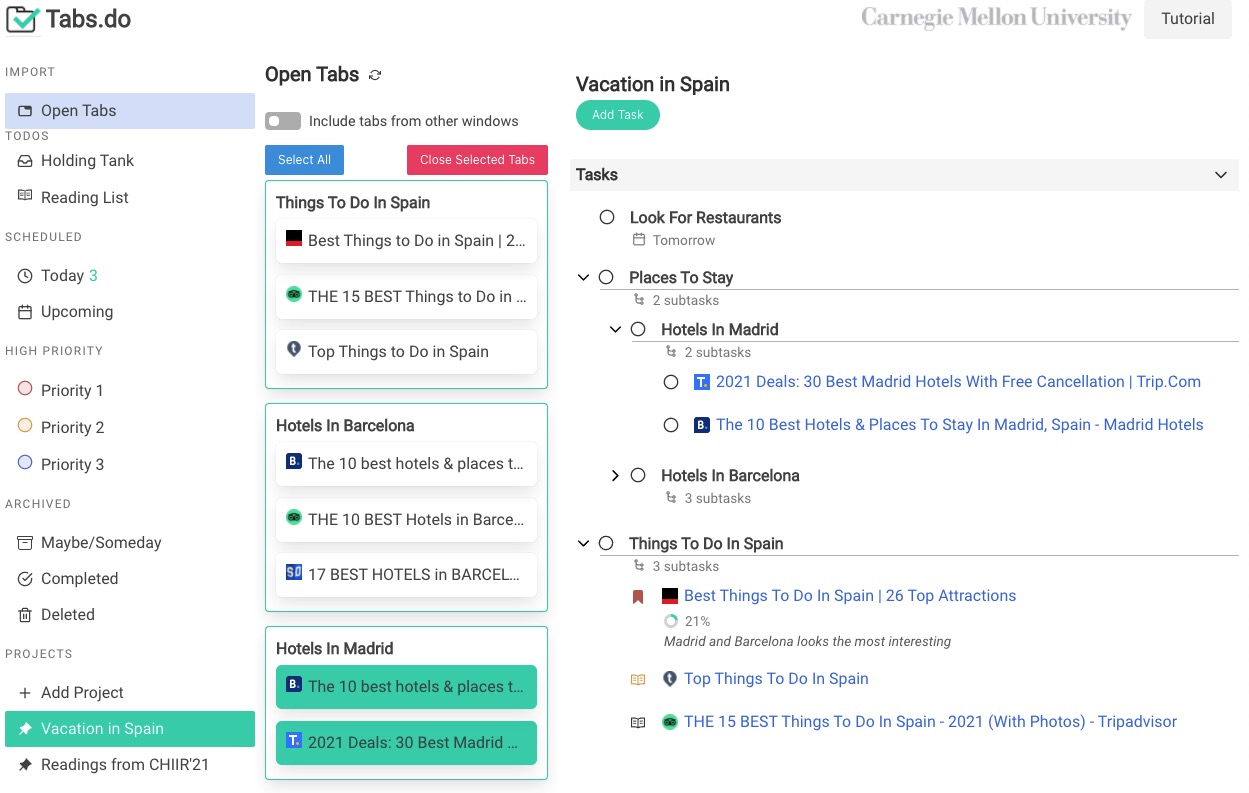
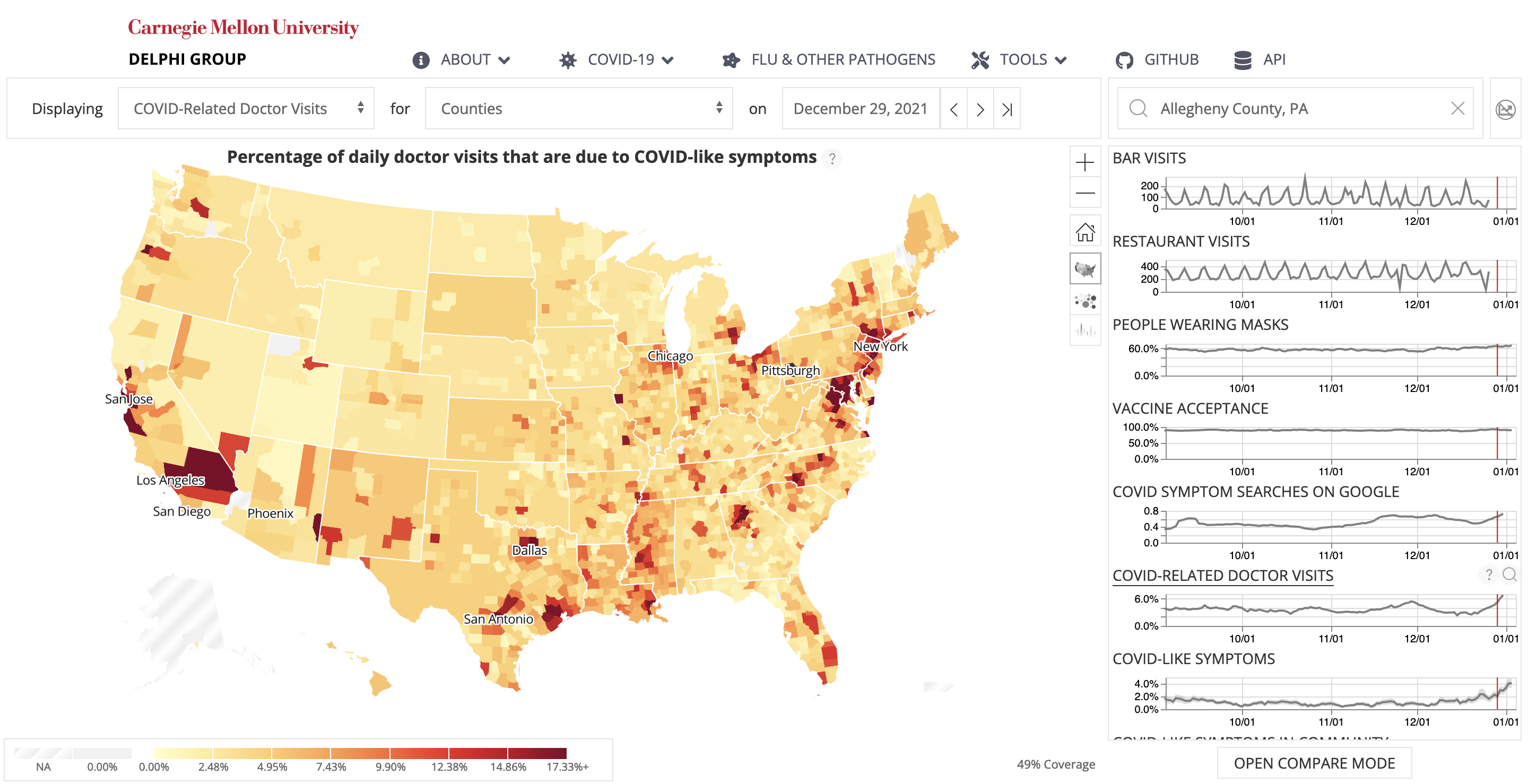
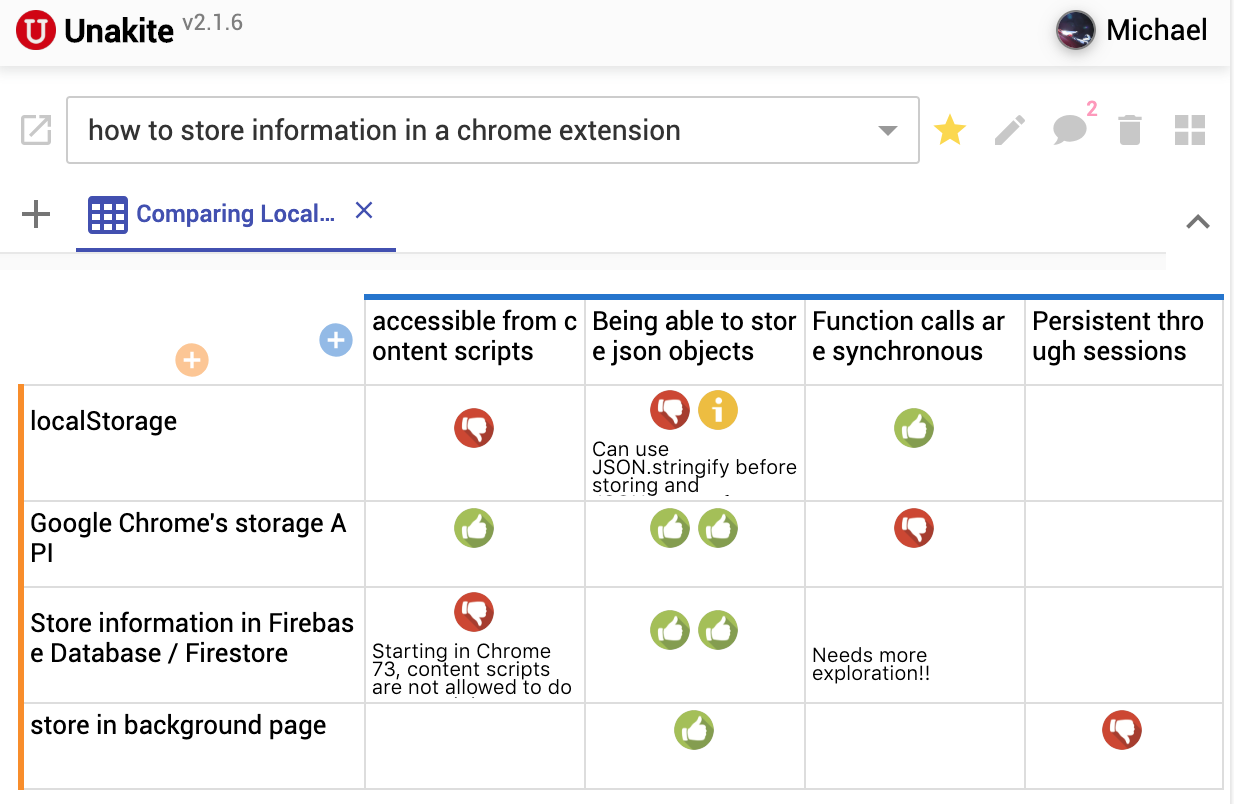
He works at the intersection of Human-computer Interaction (HCI), Programming Support Tools, Sensemaking, End-user Programming, and Intelligent User Interfaces, where he uses human-centered methods to design, build, and study interactive systems to empower individuals, especially developers, to find, collect, organize, and make sense of information online as well as to keep track of their complex decision making processes so that other individuals could also benefit.
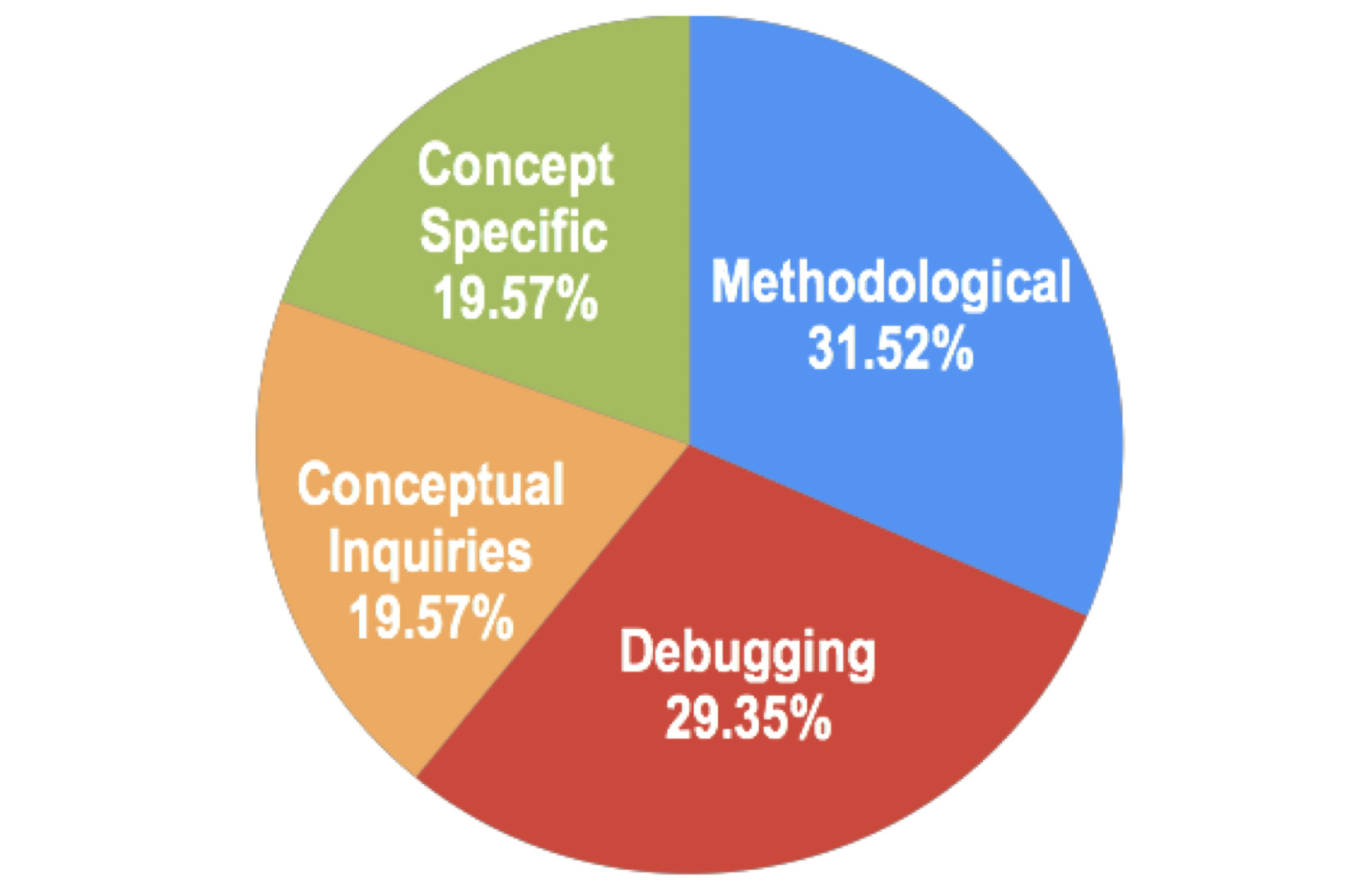
He publishes at premier HCI academic venues such as CHI, UIST, and CSCW, VIS, including three award-winning papers: a best paper honorable mention at CHI 2023, a best paper at CSCW 2021, and a best paper honorable mention at UIST 2019. His work has been generously supported by the National Science Foundation (NSF), Google, Bosch, the Office of Naval Research, and the CMU Center for Knowledge Acceleration.
Selected Open-source projects









Publications
Conferences & Pre-prints




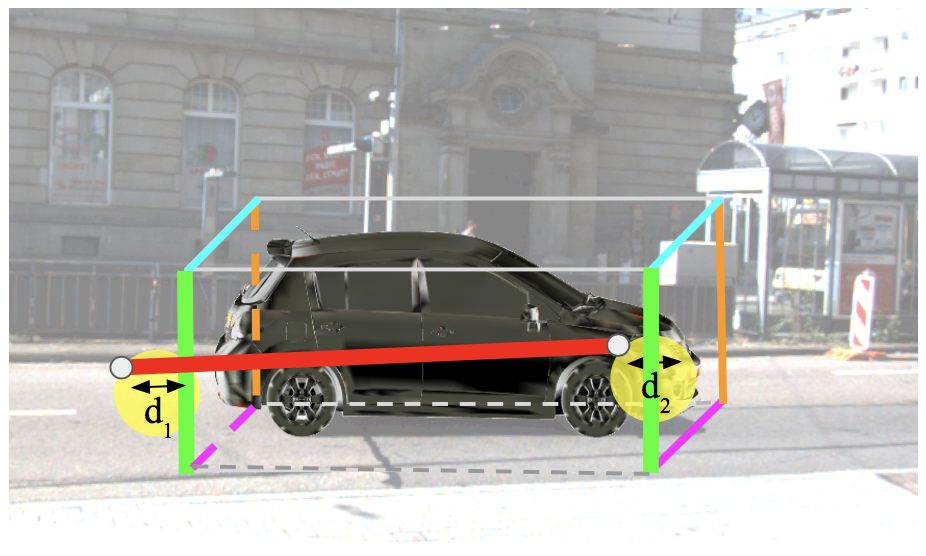
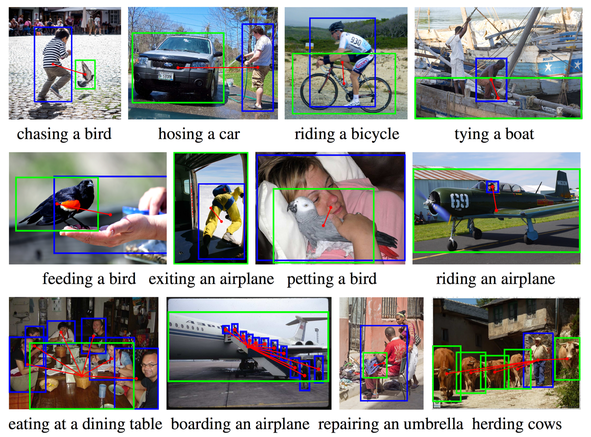
Workshop Papers & Posters