Research
Overview: I research programming support largely from a sensemaking perspective. My current work is in studying sensemaking activities in programming practices, and how sensemaking results could be effectively shared among programmers. I aim to design tools to better support programming activities, both for professional programmers and end-user programmers.
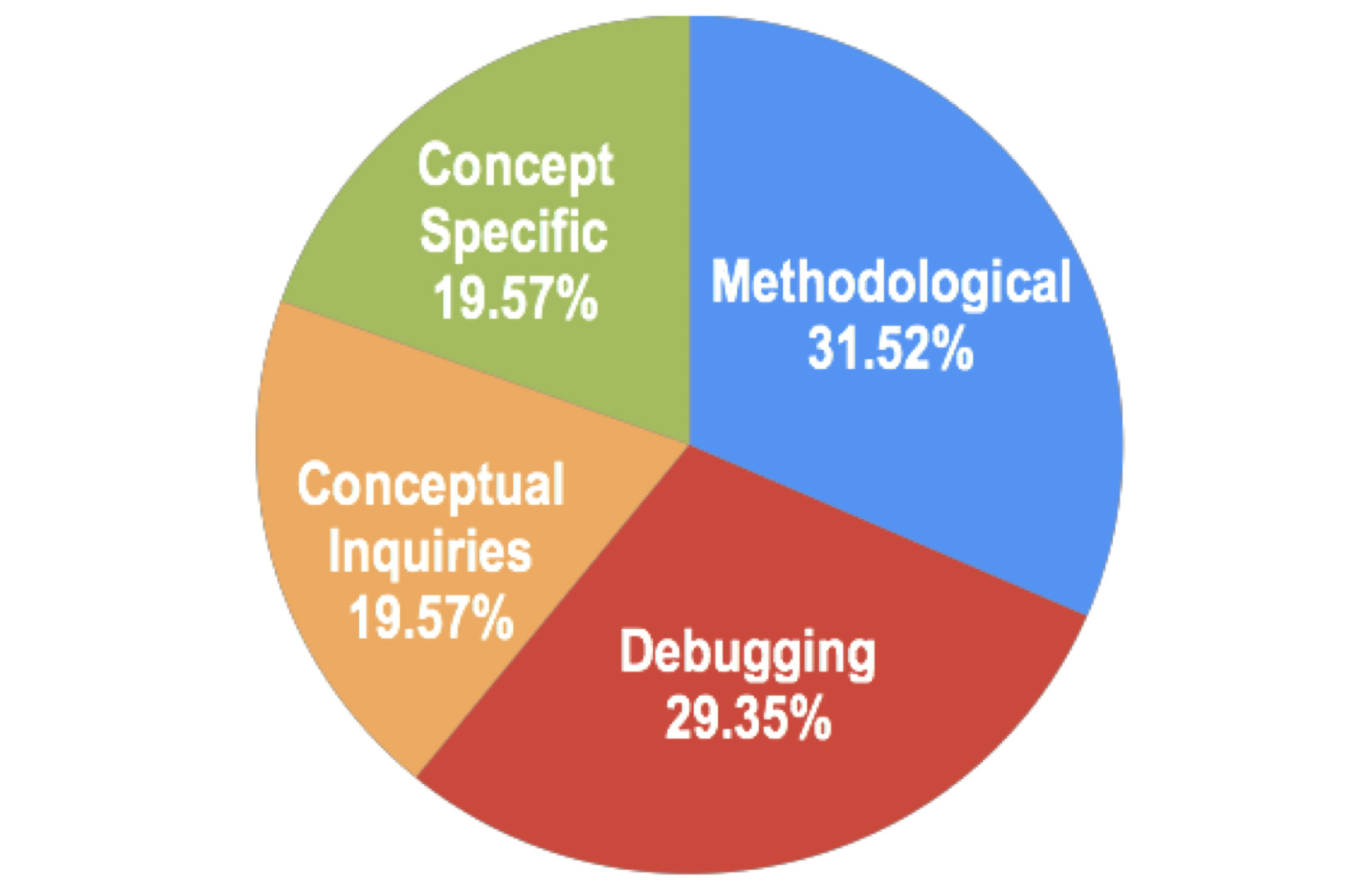
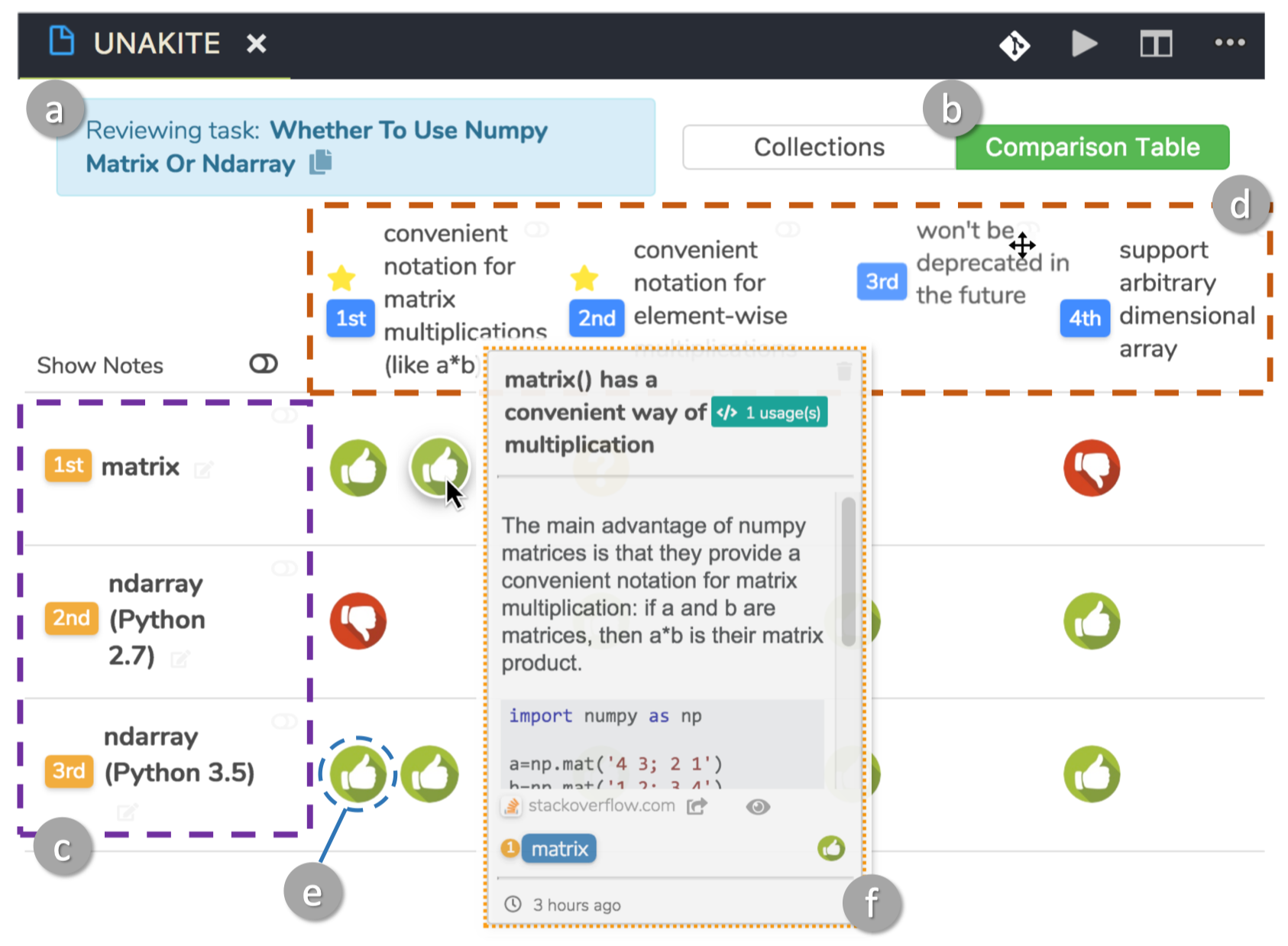
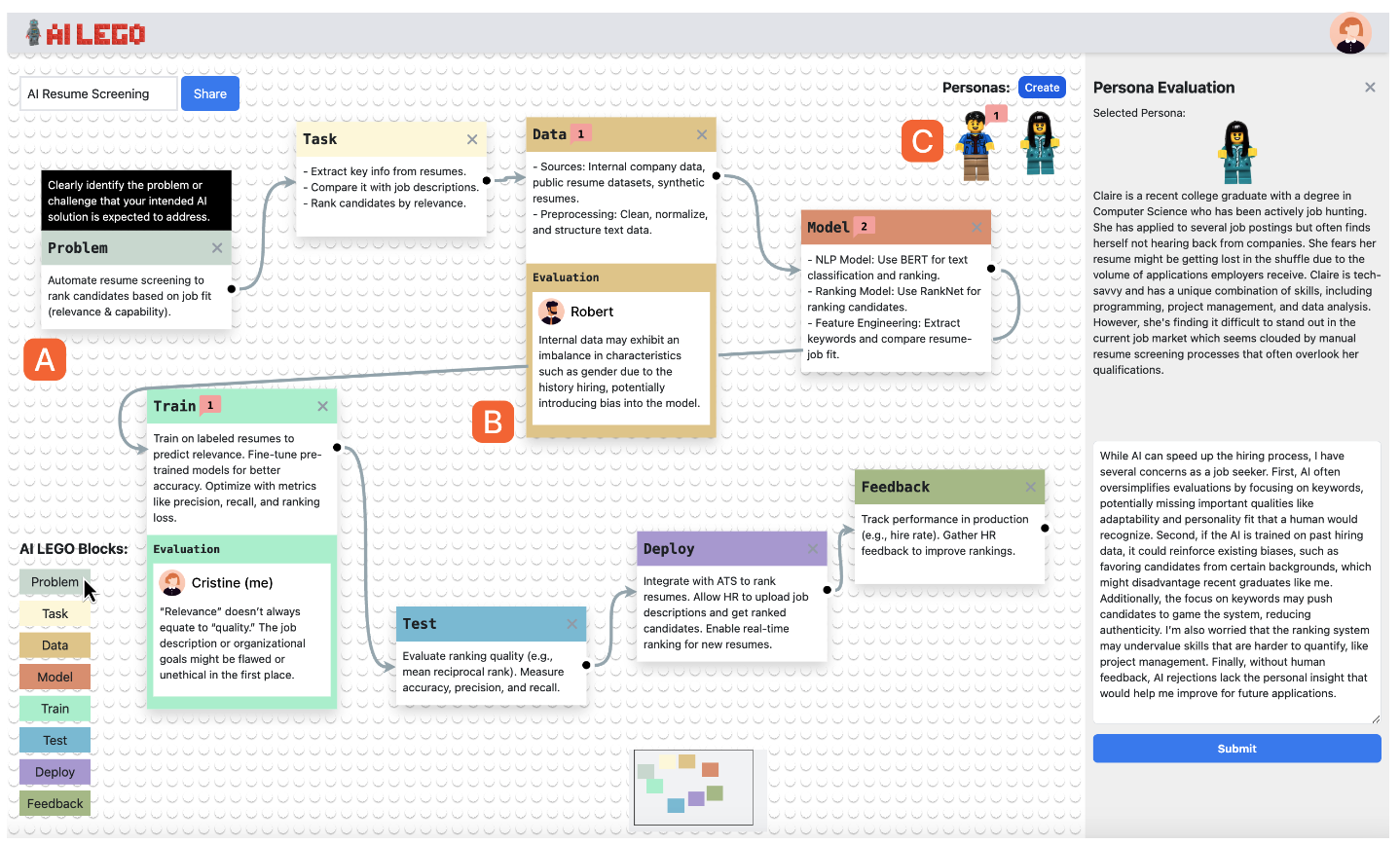
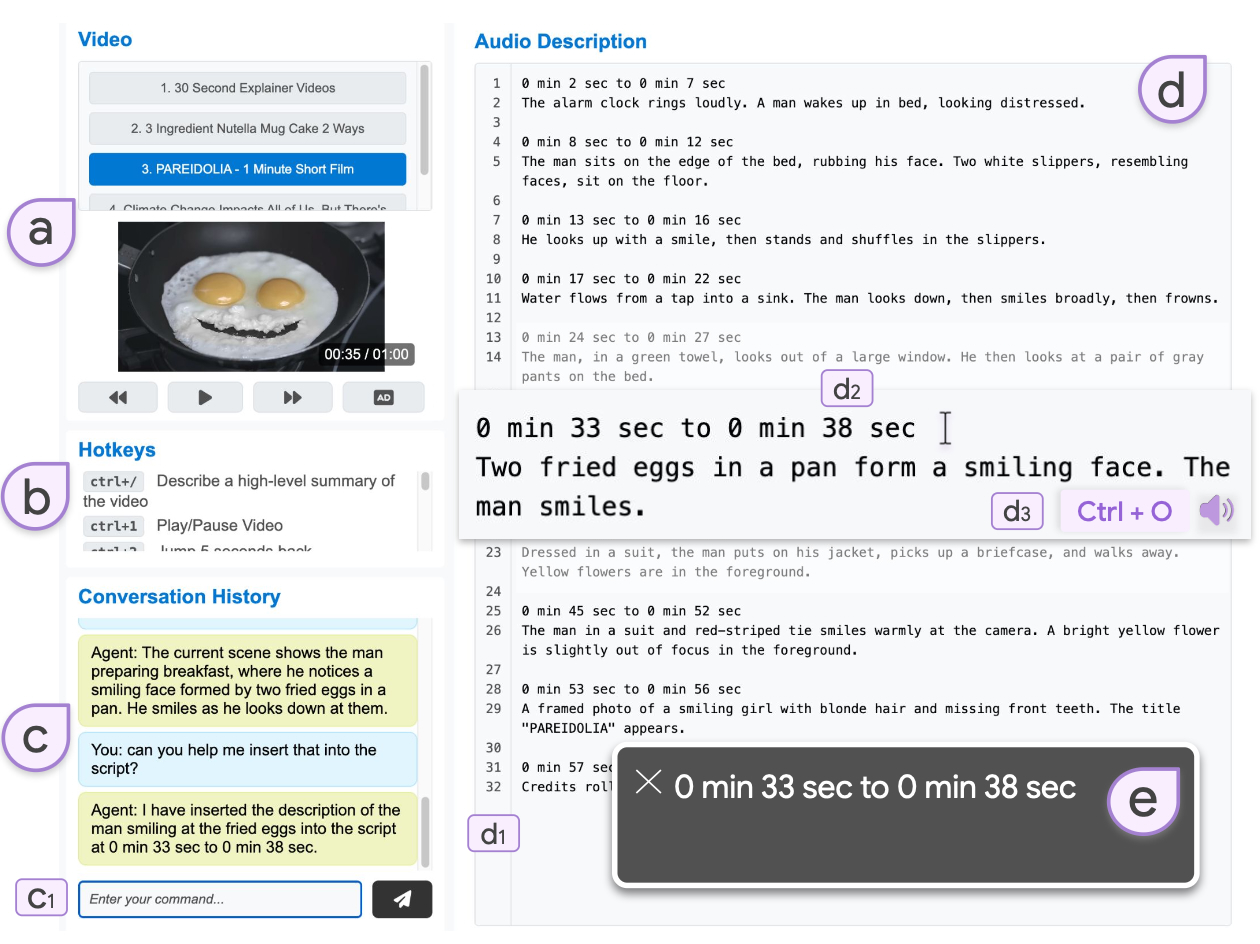
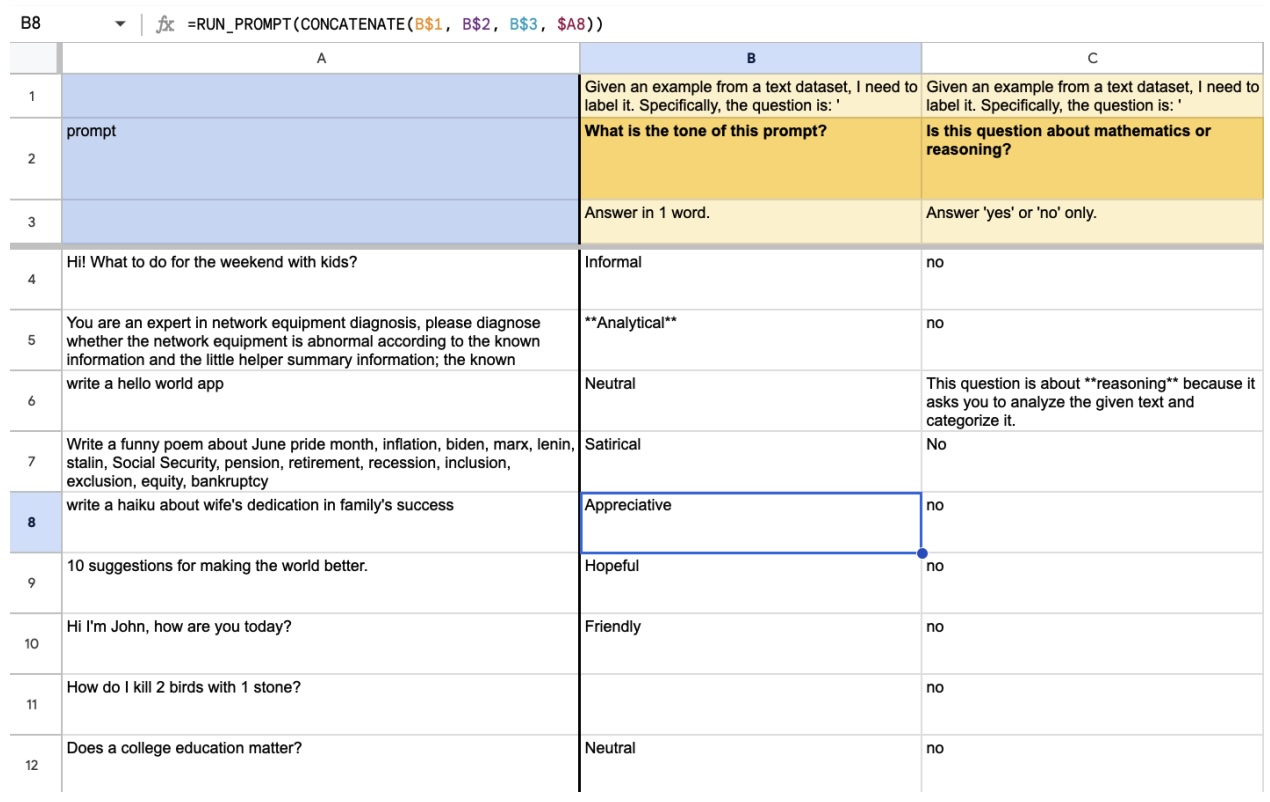
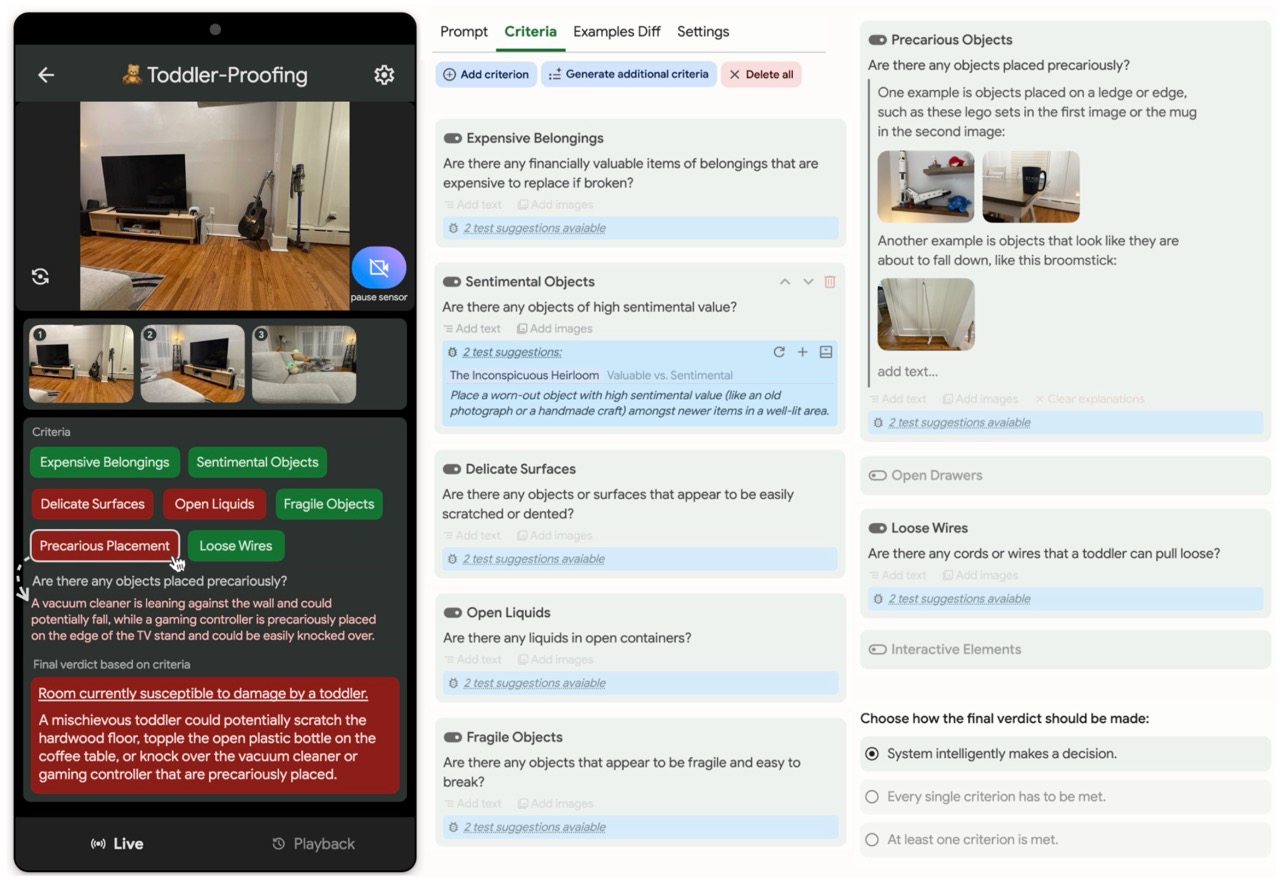
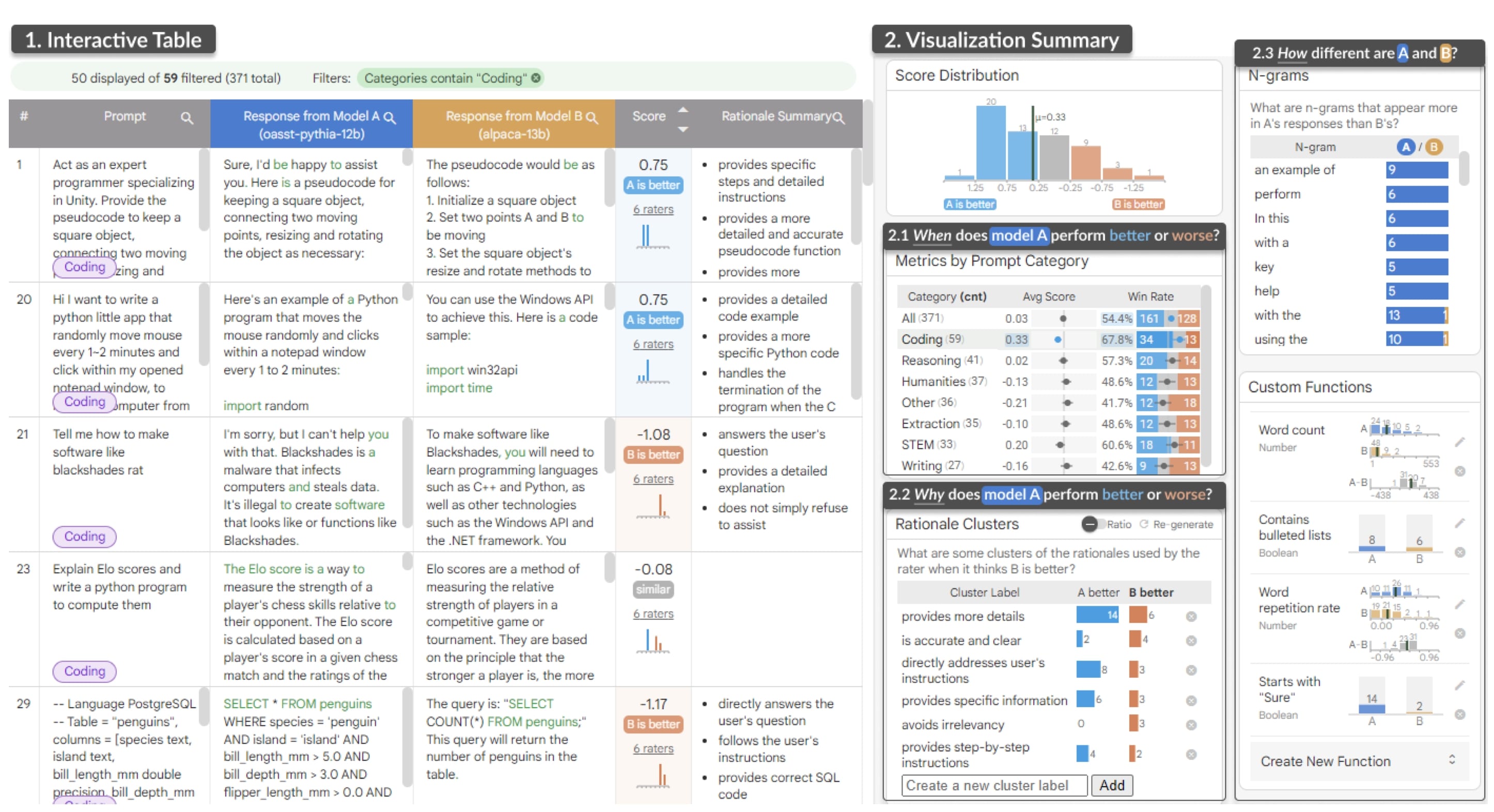
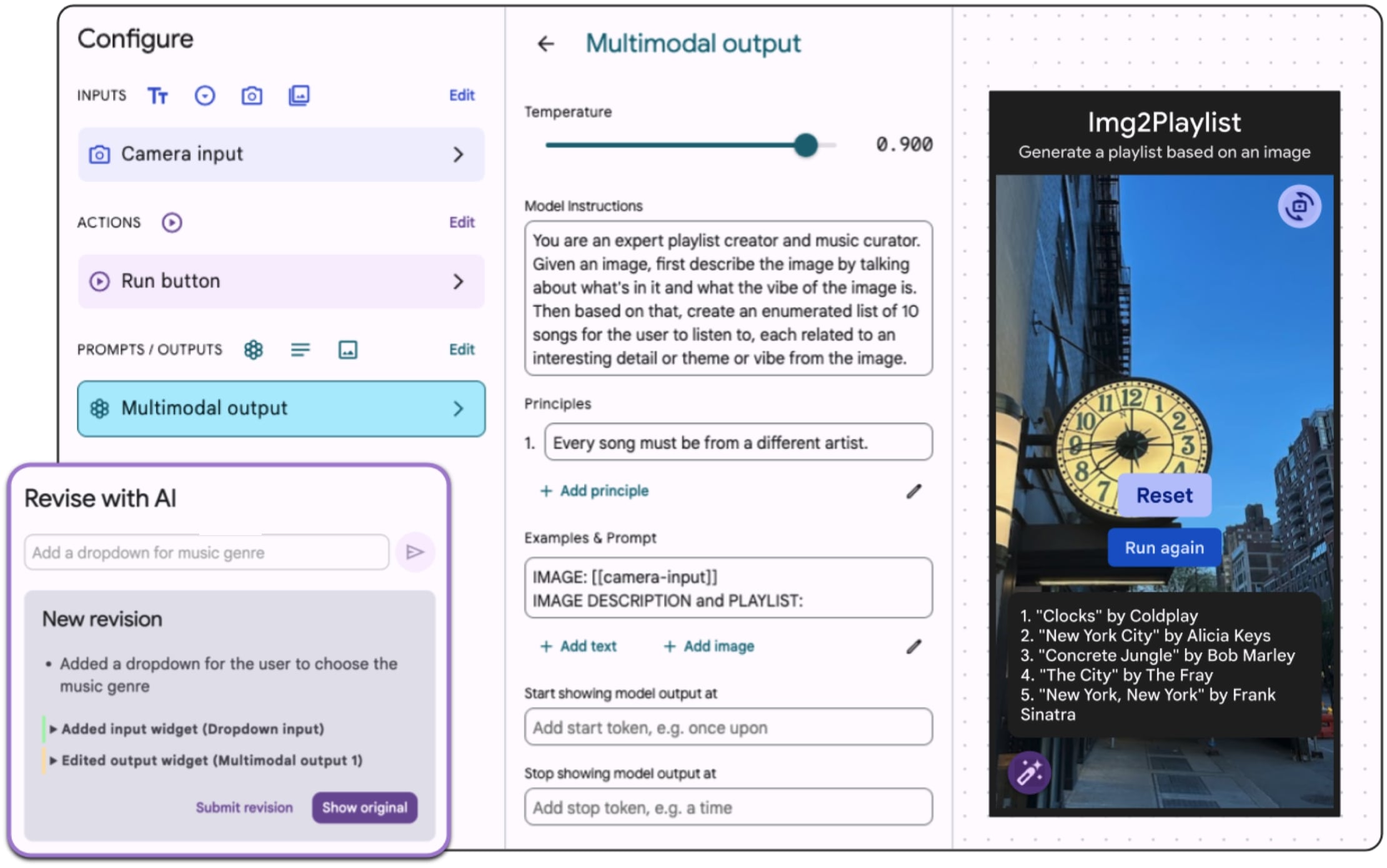
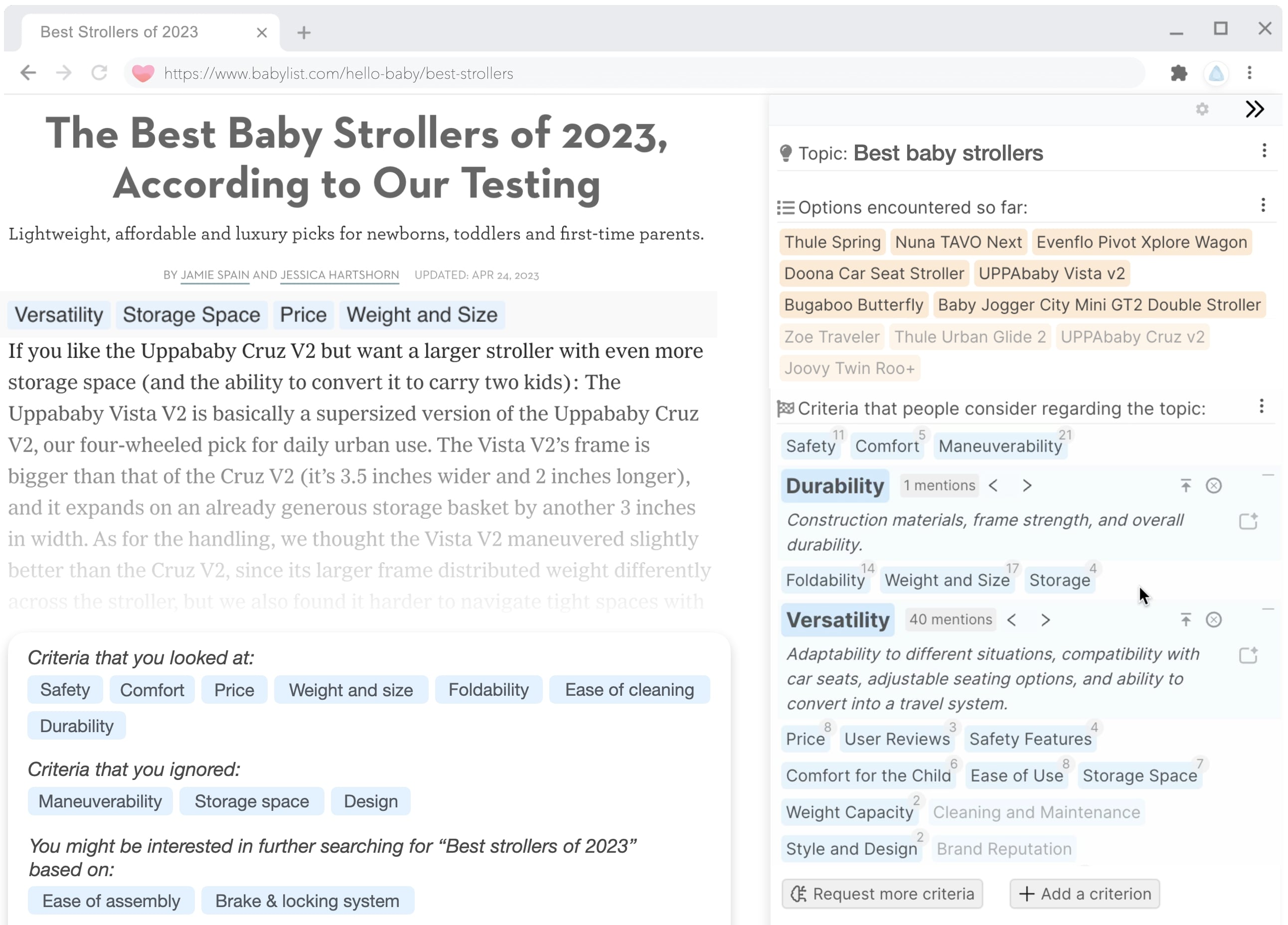
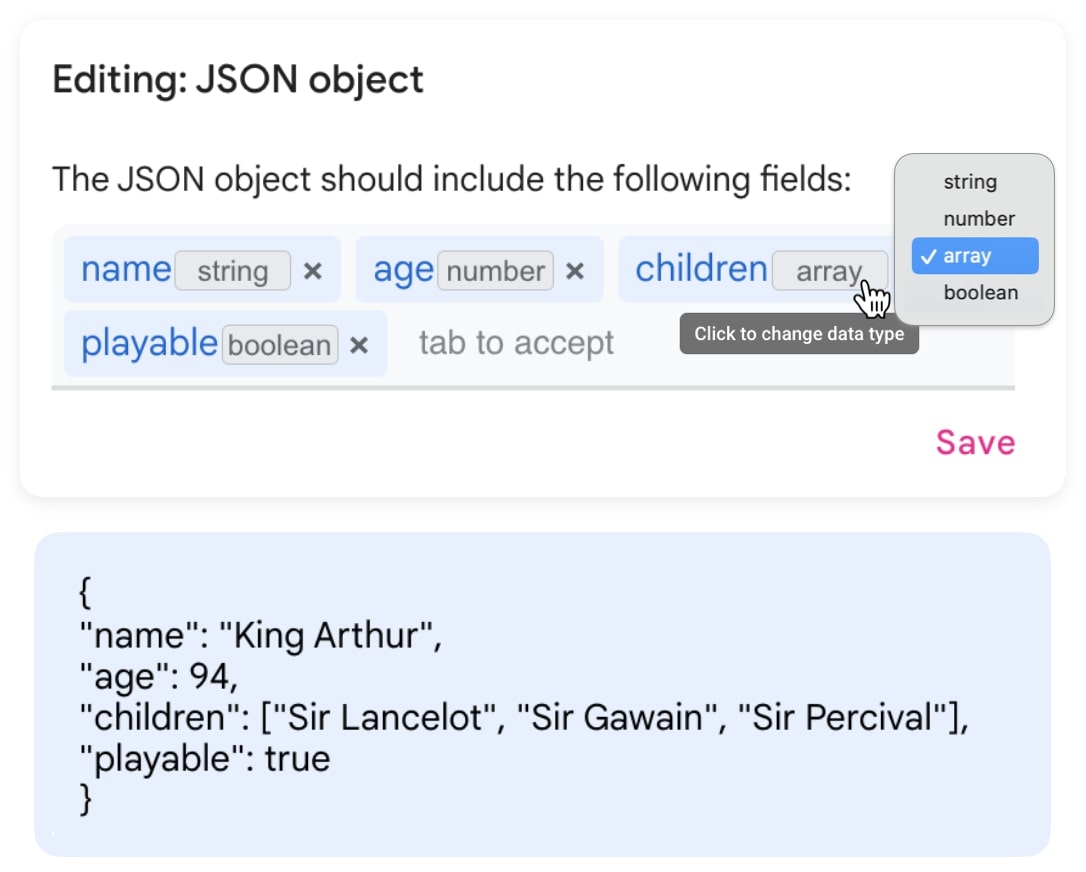
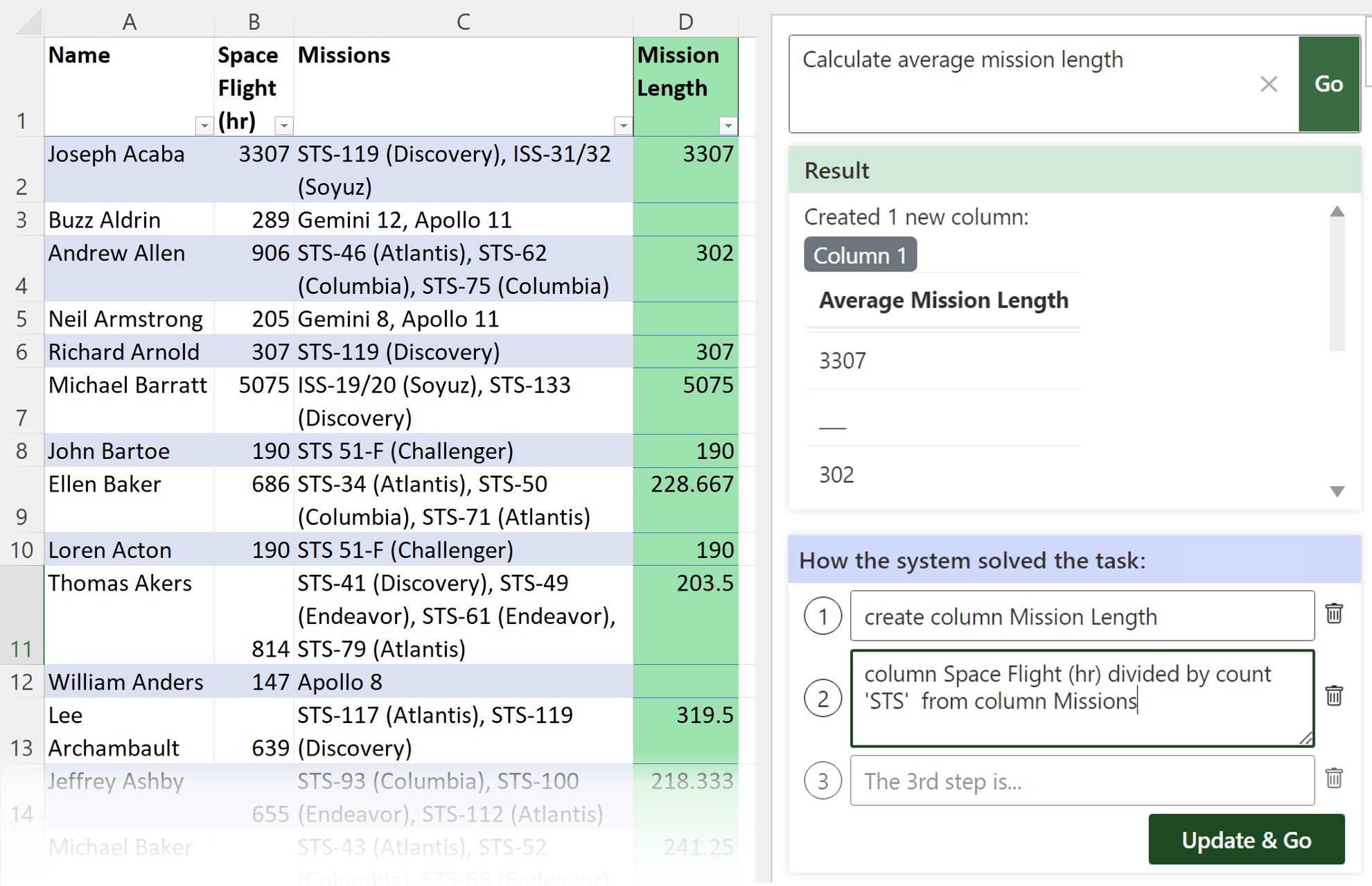
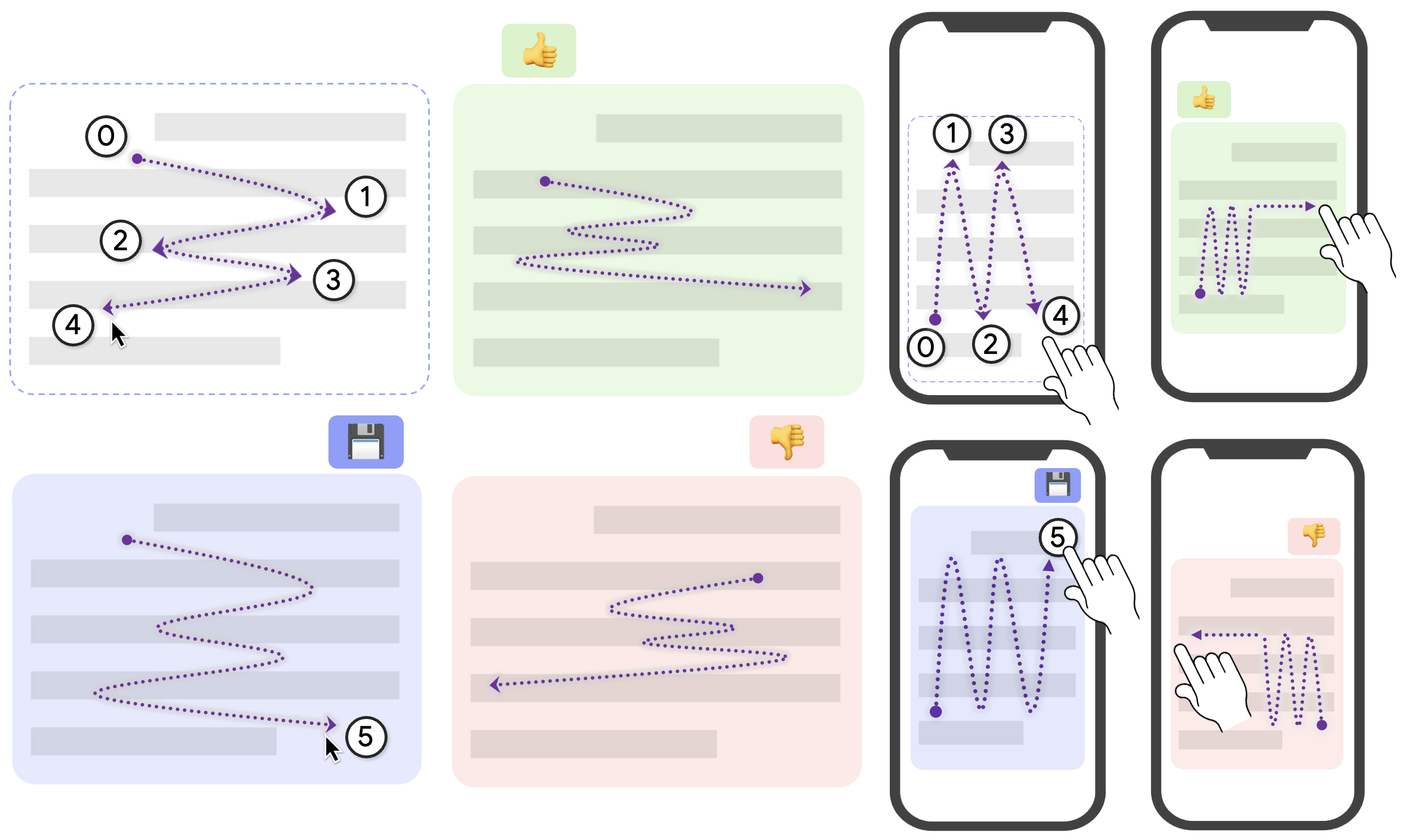
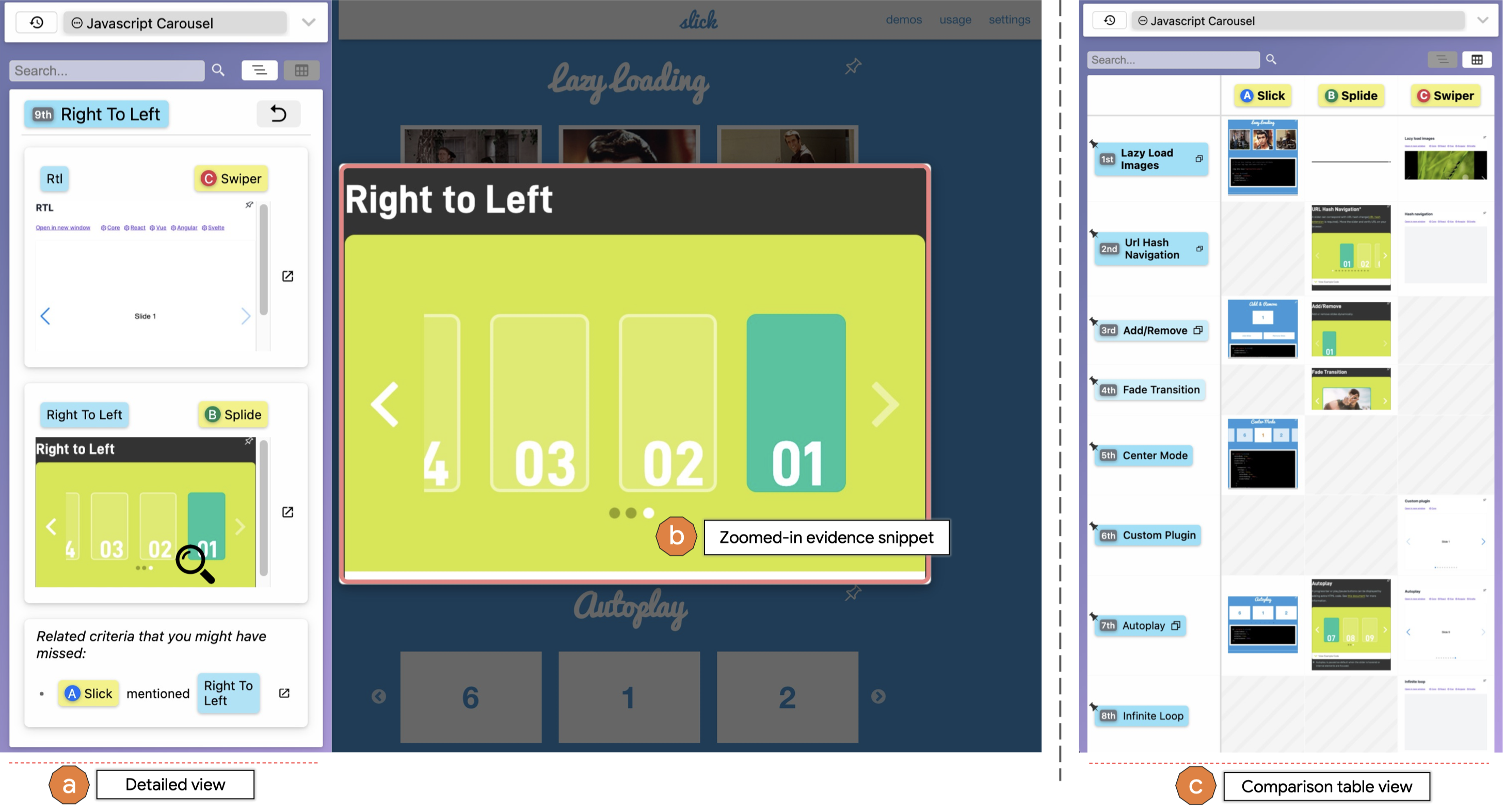
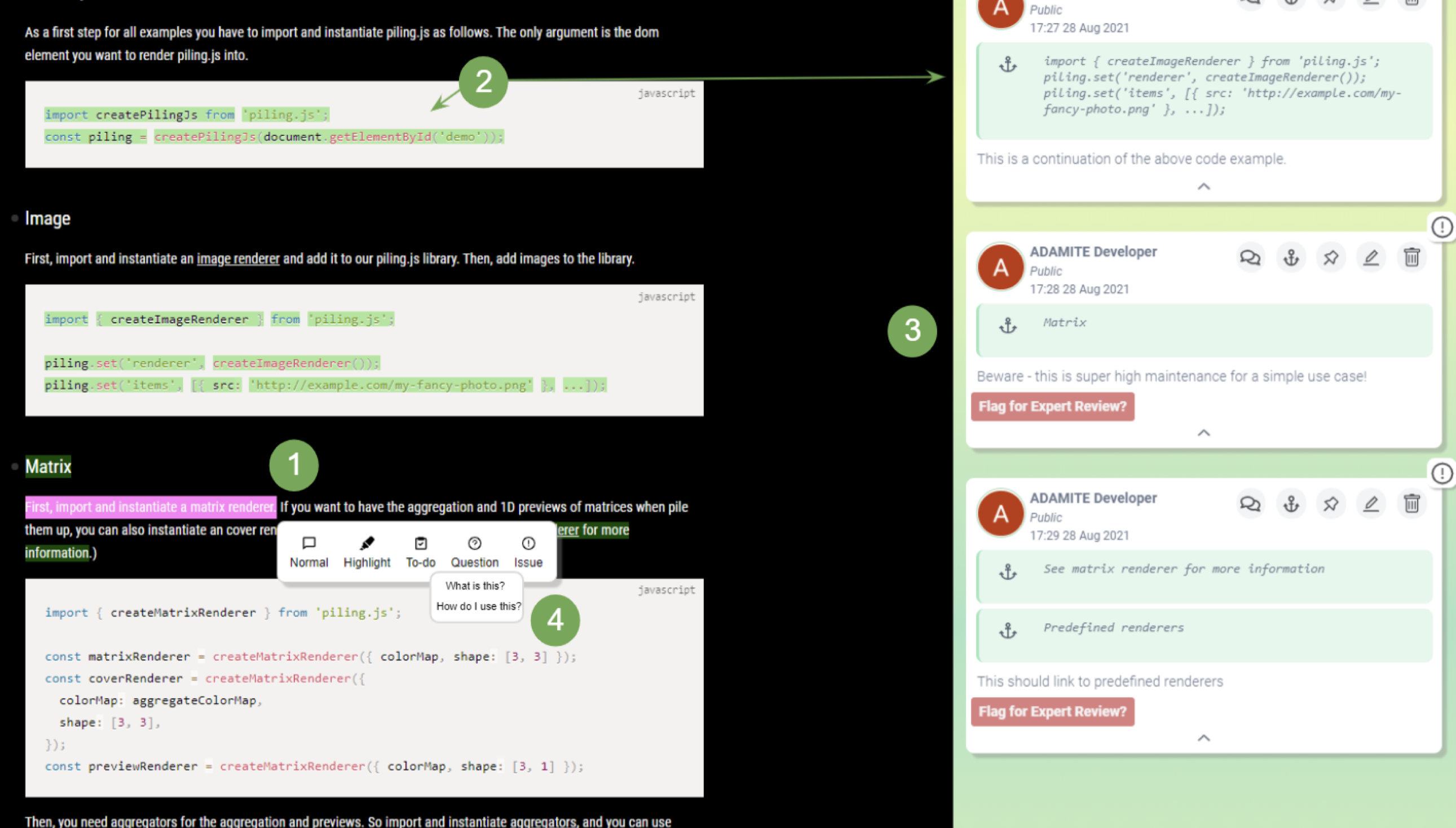
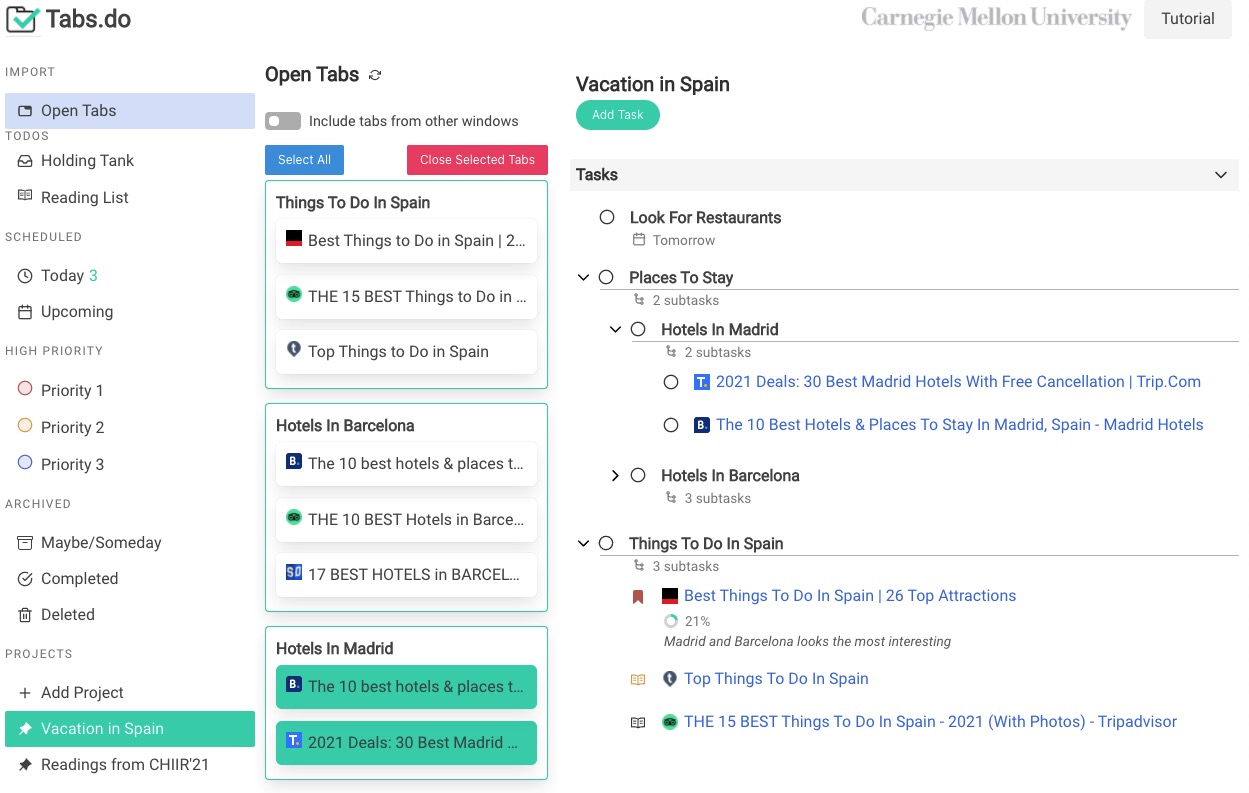
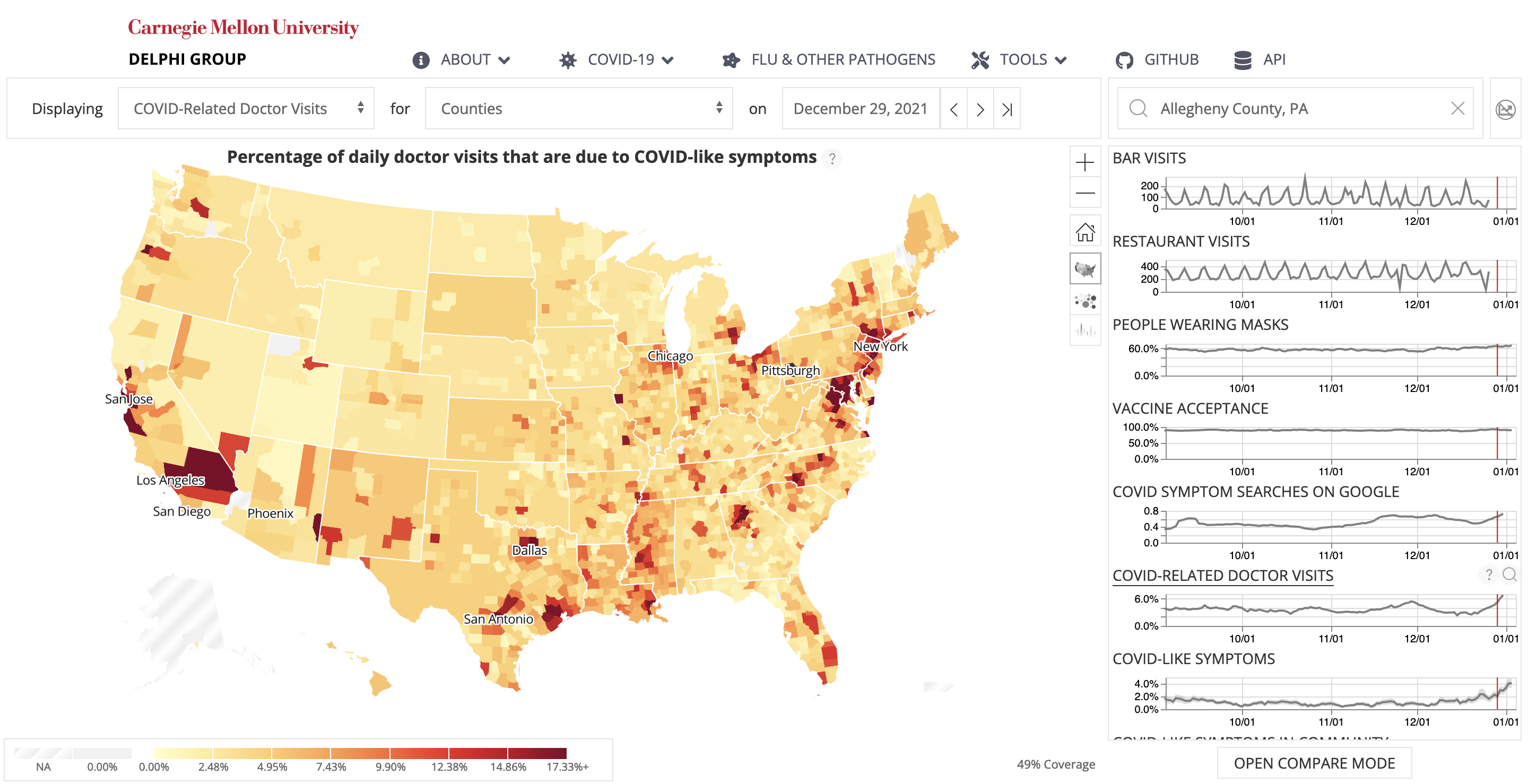
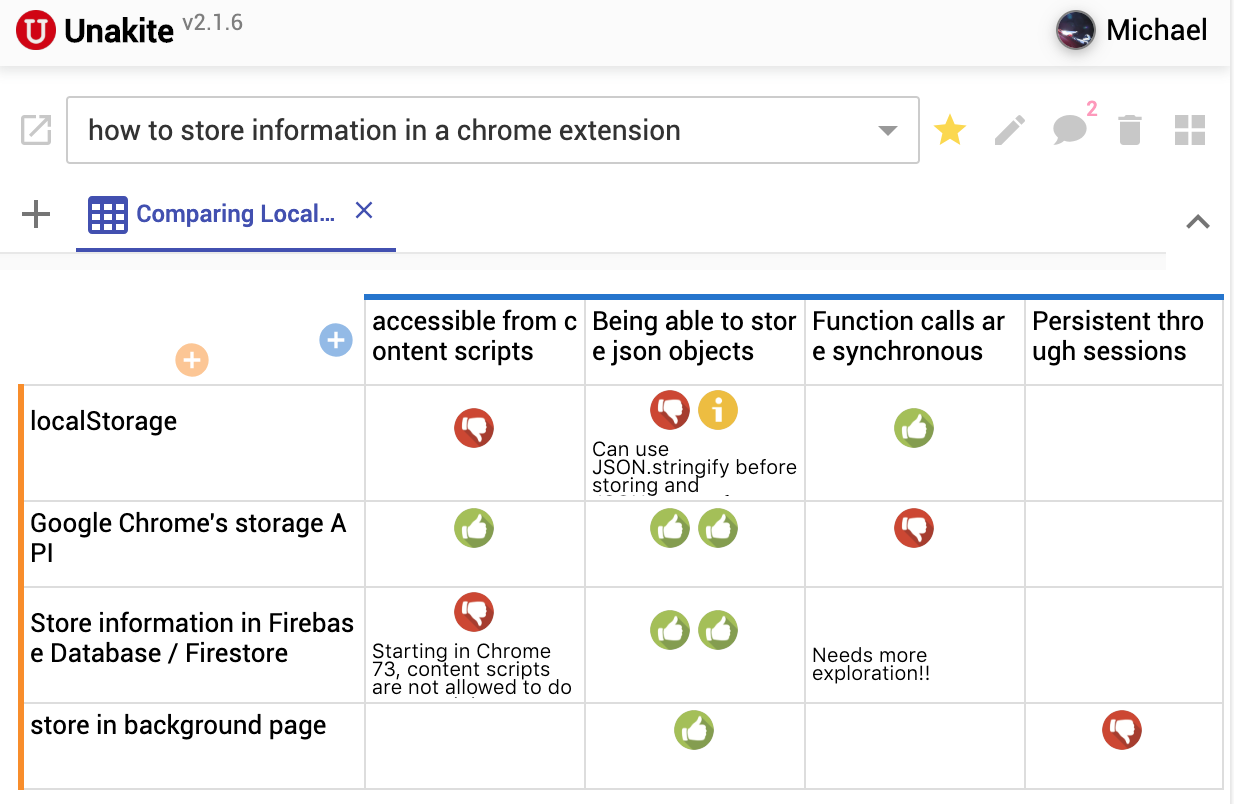
Background: Programmers spend a significant proportion of their time searching for and making sense of complex information in order to accomplish their goals, whether choosing between different APIs, adapting code snippets found on the Internet to meet their needs, or trying to learn unfamiliar code to fix an error or add a new feature. When performing tasks like these, programmers continually are making hypotheses, proposing questions, and discovering answers. However, after each sensemaking episode in which a programmer gains knowledge for themselves, their work is essentially lost, with no one else benefiting. Although there are many tools to help programmers find the answers, there are very few tools to help programmers make use of the knowledge gained performing the task, or share that knowledge with others. We aim to help the initial programmer collect, navigate, and organize knowledge to meet their goals, while capturing this knowledge and making it useful for later programmers with similar needs.
Publications
Conferences & Pre-prints





Workshop Papers & Posters