Michael Xieyang Liu
Research Scientist @ Google DeepMind
Michael Xieyang Liu is a Research Scientist at Google DeepMind in the PAIR (People + AI Research Initiative) team. His research aims to improve human-AI interaction, with a particular focus on human interaction with multimodal large language models and controllable AI.
He previously earned his Ph.D. from the Human-Computer Interaction Institute @ Carnegie Mellon University, where he was advised by Dr. Brad A. Myers and Dr. Niki Kittur. During his Ph.D., he interned at the RiSE group and Calc Intelligence group at Microsoft Research, the Google Cloud team at Google, and Bosch Research.
He works at the intersection of Human-computer Interaction (HCI), Programming Support Tools, Sensemaking, End-user Programming, and Intelligent User Interfaces, where he uses human-centered methods to design, build, and study interactive systems to empower individuals, especially developers, to find, collect, organize, and make sense of information online as well as to keep track of their complex decision making processes so that other individuals could also benefit.
He publishes at premier HCI academic venues such as CHI, UIST, and CSCW, VIS, including three award-winning papers: a best paper honorable mention at CHI 2023, a best paper at CSCW 2021, and a best paper honorable mention at UIST 2019. His work has been generously supported by the National Science Foundation (NSF), Google, Bosch, the Office of Naval Research, and the CMU Center for Knowledge Acceleration.
Selected Open-source projects









Publications
Conferences & Pre-prints
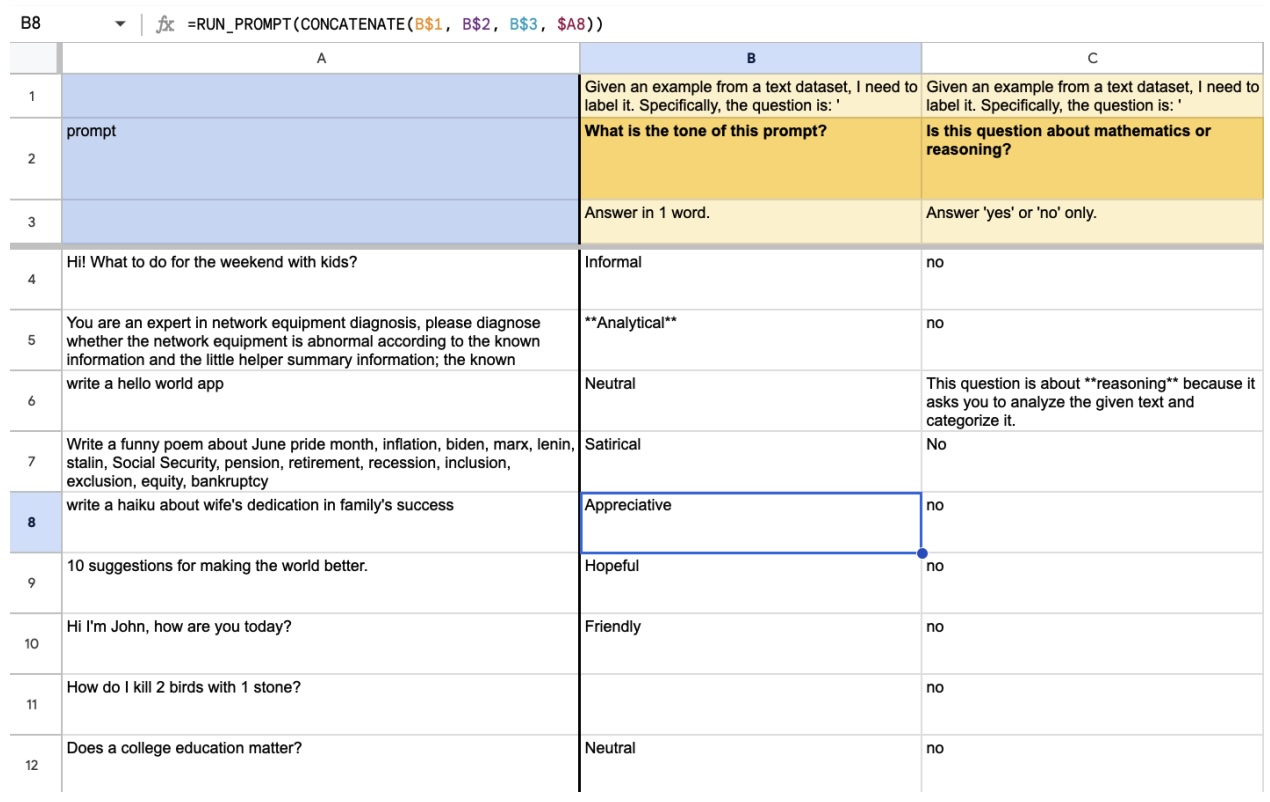
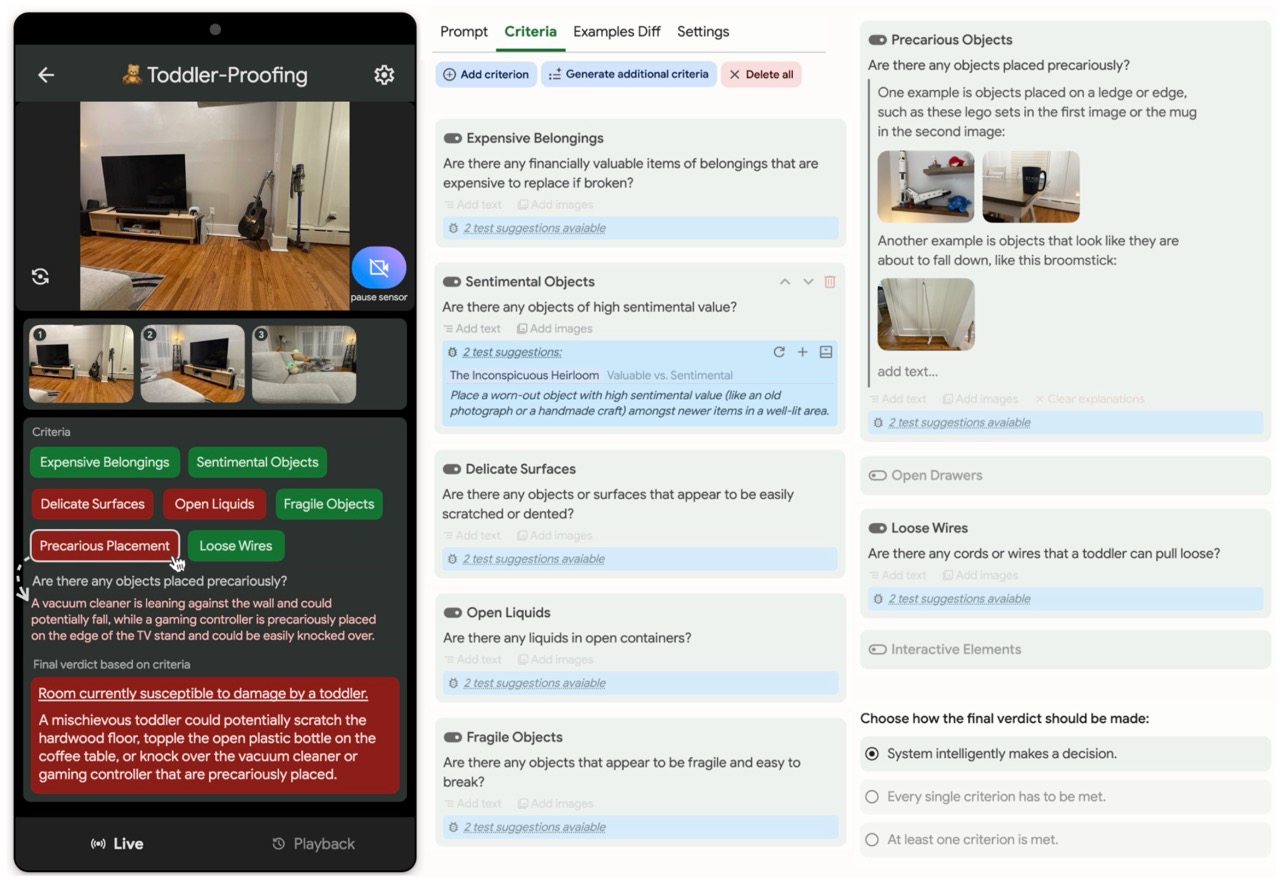
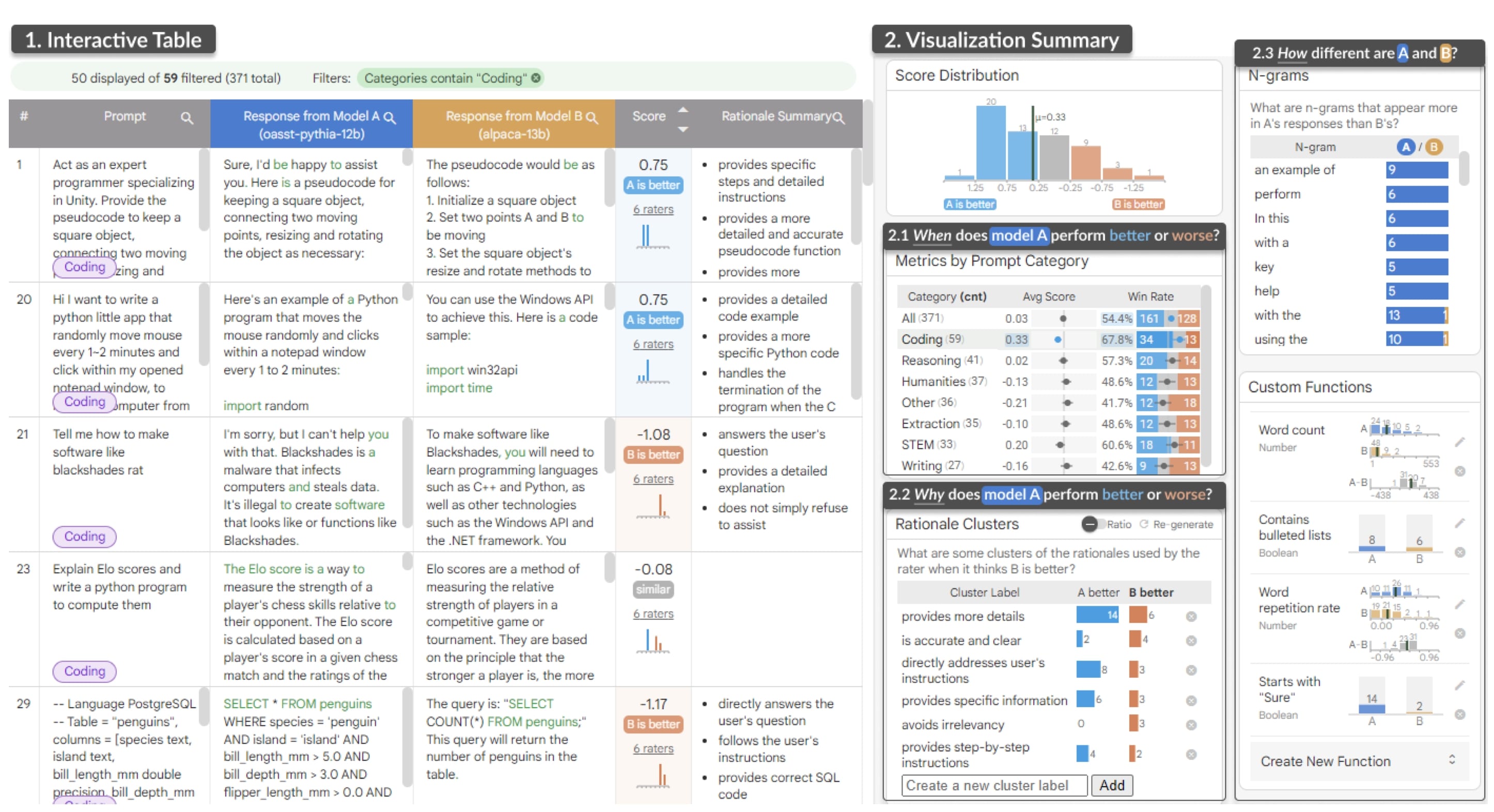
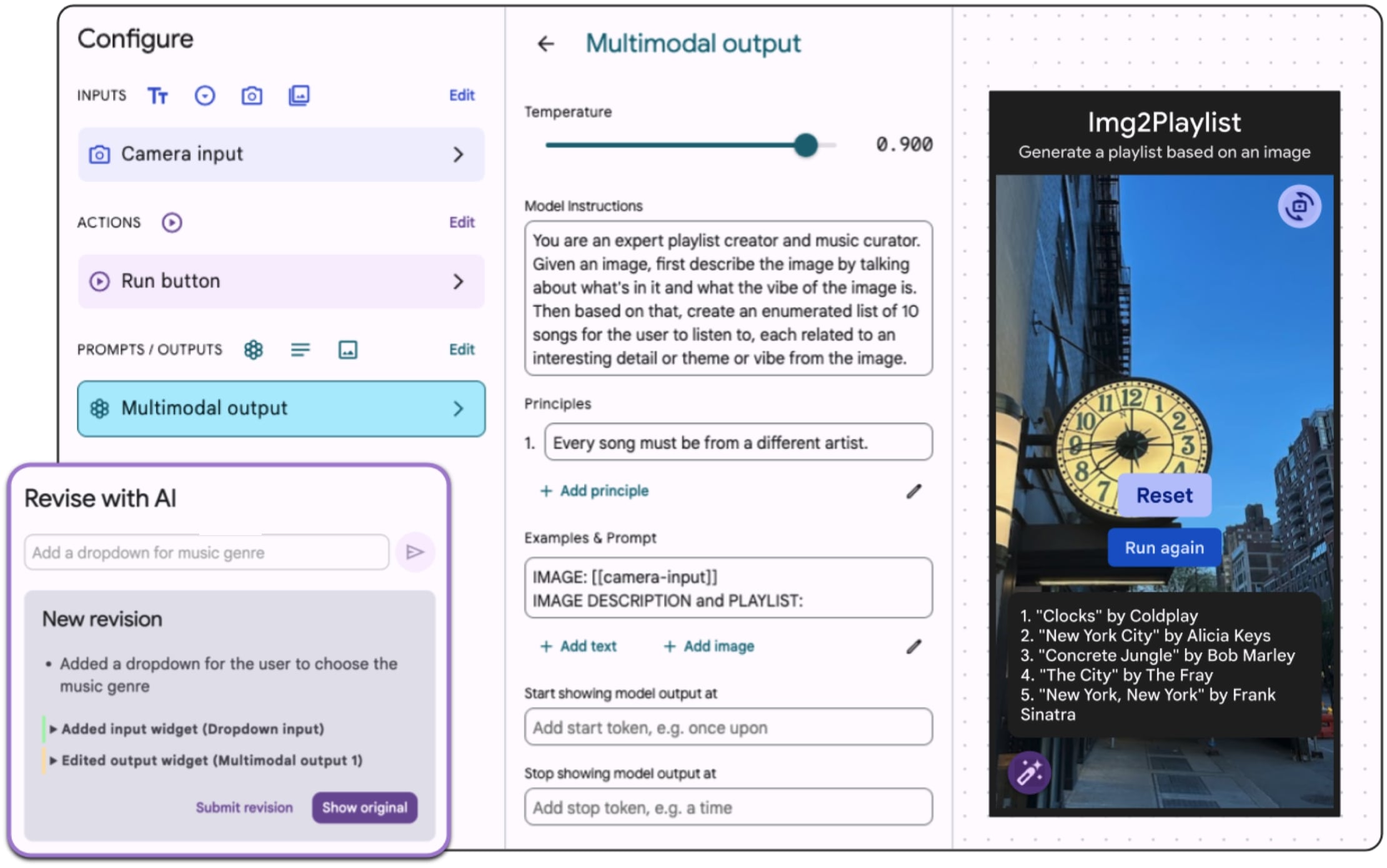




Workshop Papers & Posters

News
- 2 years ago
I joined Google DeepMind as a Research Scientist!
- 2 years ago
I passed my Ph.D. thesis defense!
- 2 years ago
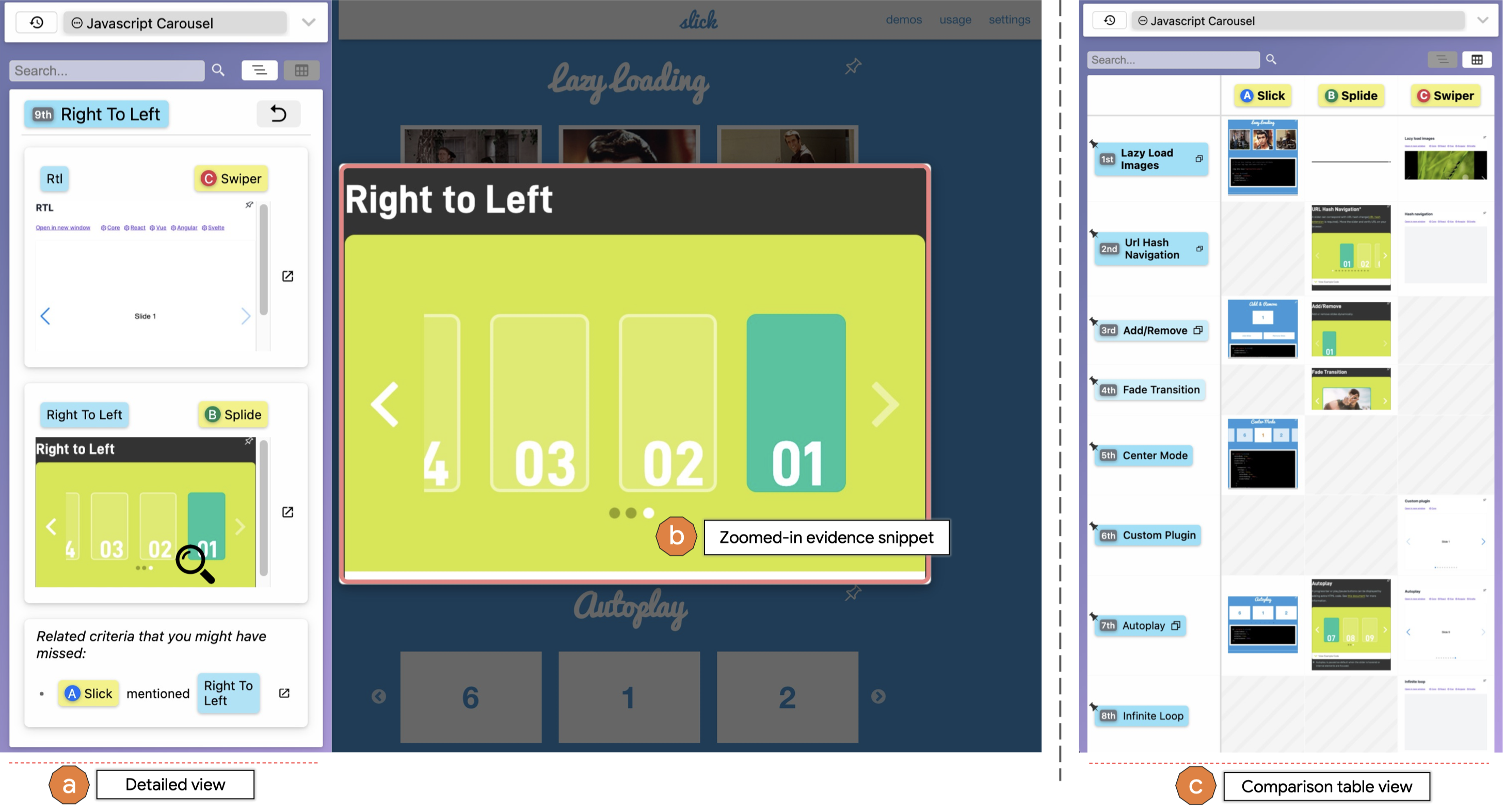
Our full paper "What It Wants Me To Say": Bridging the Abstraction Gap Between End-User Programmers and Code-Generating Large Language Models just won a 🏆 Best Paper Honorable Mention Award at CHI 2023! Check it out here!
- 2 years ago
I passed my thesis proposal! One step closer to graduation! Here's my proposal document and slides.
- 3 years ago
Our full paper Wigglite: Low-cost Information Collection and Triage was conditionally accepted to UIST 2022! .
- 4 years ago
Our two full papers Crystalline: Lowering the Cost for Developers to Collect and Organize Information for Decision Making and Understanding How Programmers Can Use Annotations on Documentation are conditionally accepted to CHI 2022! .
- 4 years ago
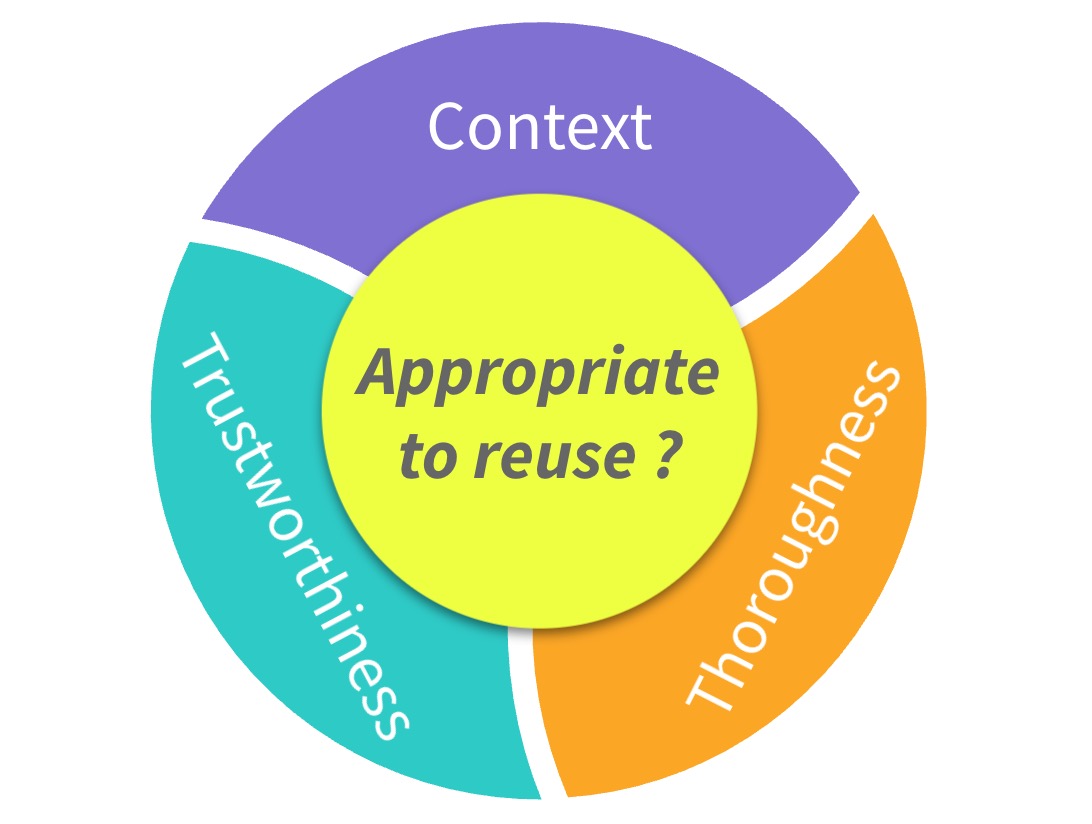
Our full paper To Reuse or Not To Reuse? A Framework and System for Evaluating Summarized Knowledge just won a 🏆 Best Paper Award at CSCW 2021! Check it out here! Also check out this piece of news ccoverage from CMU SCS!
- 4 years ago
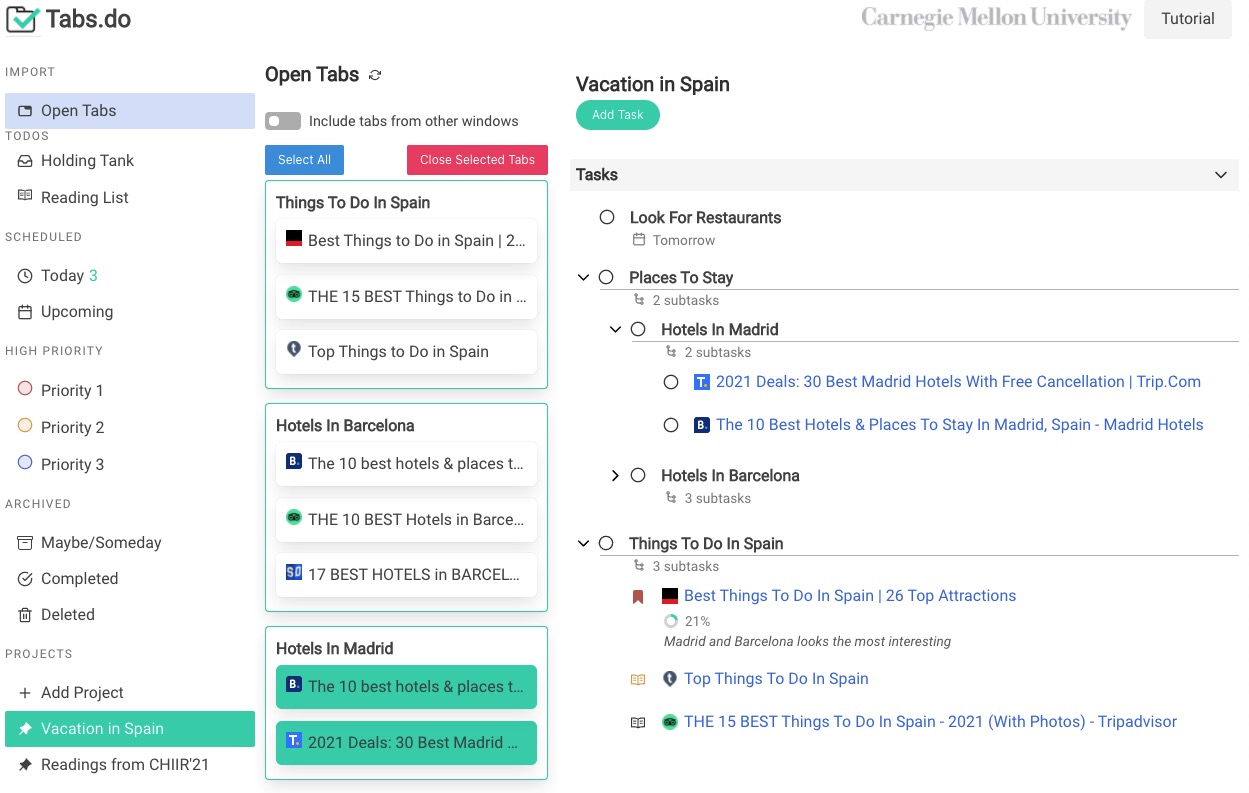
Our full paper Tabs.do: Task-Centric Browser Tab Management is accepted to UIST 2021! Check it out here.
- 4 years ago
Our full paper To Reuse or Not To Reuse? A Framework and System for Evaluating Summarized Knowledge is accepted to CSCW 2021! Check it out here.
- 5 years ago
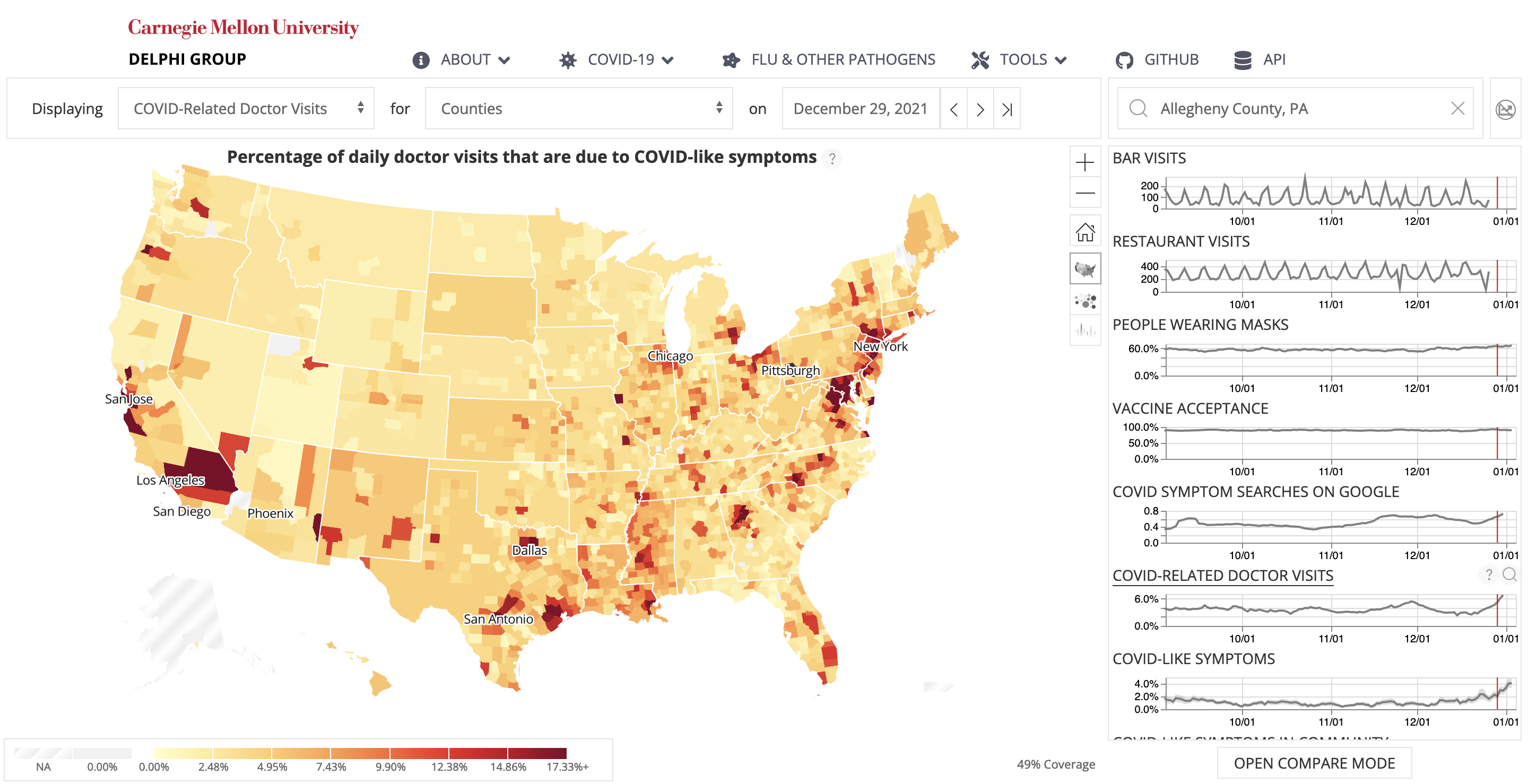
Check out our COVIDcast system, which displays indicators related to COVID-19 activity level across the U.S.
CMU news coverage: Carnegie Mellon Unveils Five Interactive COVID-19 Maps.
Honored to be on this team and contribute! - 6 years ago
I presented our full paper Unakite: Scaffolding Developers’ Decision-Making Using the Web at UIST 2019 in New Orleans. It received a 🏅 Best Paper Honorable Mention Award! Check it out here.
- 6 years ago
I just updated my Ionic template app called Ionic Audio Player with the latest version of Ionic and Angular. Can't believe it's been two years since I last updated it. It's a great starting point for devs who would like to build an audio player using the Ionic Framework. Please check it out!
- 6 years ago
Our full paper Unakite: Scaffolding Developers’ Decision-Making Using the Web is accepted to ACM UIST 2019. It also received a 🏅 Best Paper Honorable Mention Award! Check it out here.
- 6 years ago
Tired of looking for a tab among the 50 tabs you opened ? The Vertical Tabs Chrome extension I made as a hobby project might help you with that! [Source code]
- 6 years ago
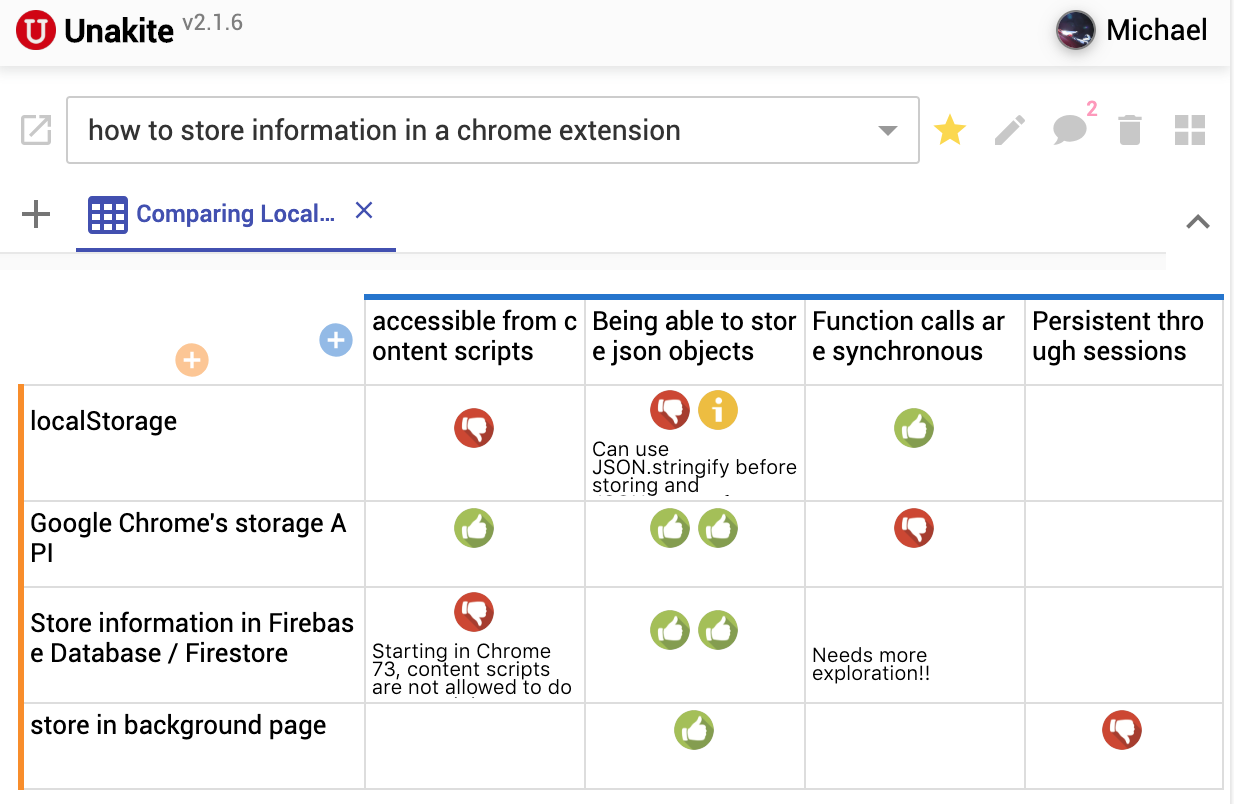
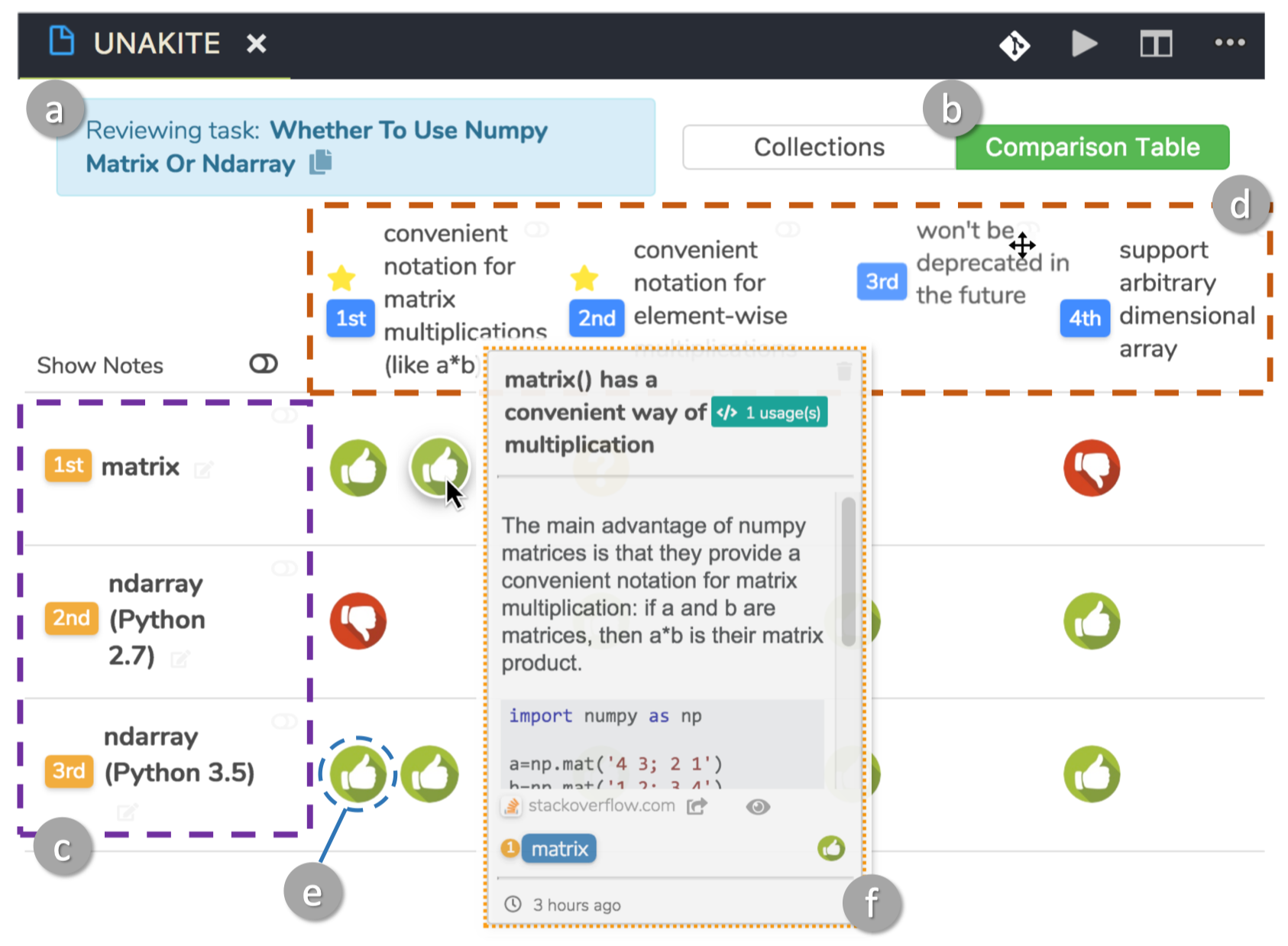
Please try Unakite, our new plugin for Chrome to help programmers organize information found on the web!
- 6 years ago
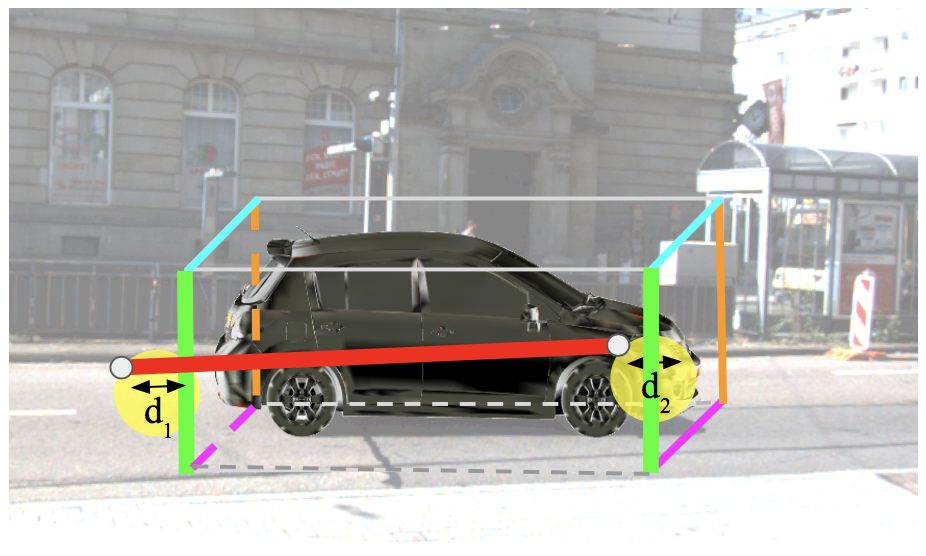
Our full paper Popup: Reconstructing 3D Video Using Particle Filtering to Aggregate Crowd Responses is accepted to ACM IUI 2019. Check it out here.
- 7 years ago
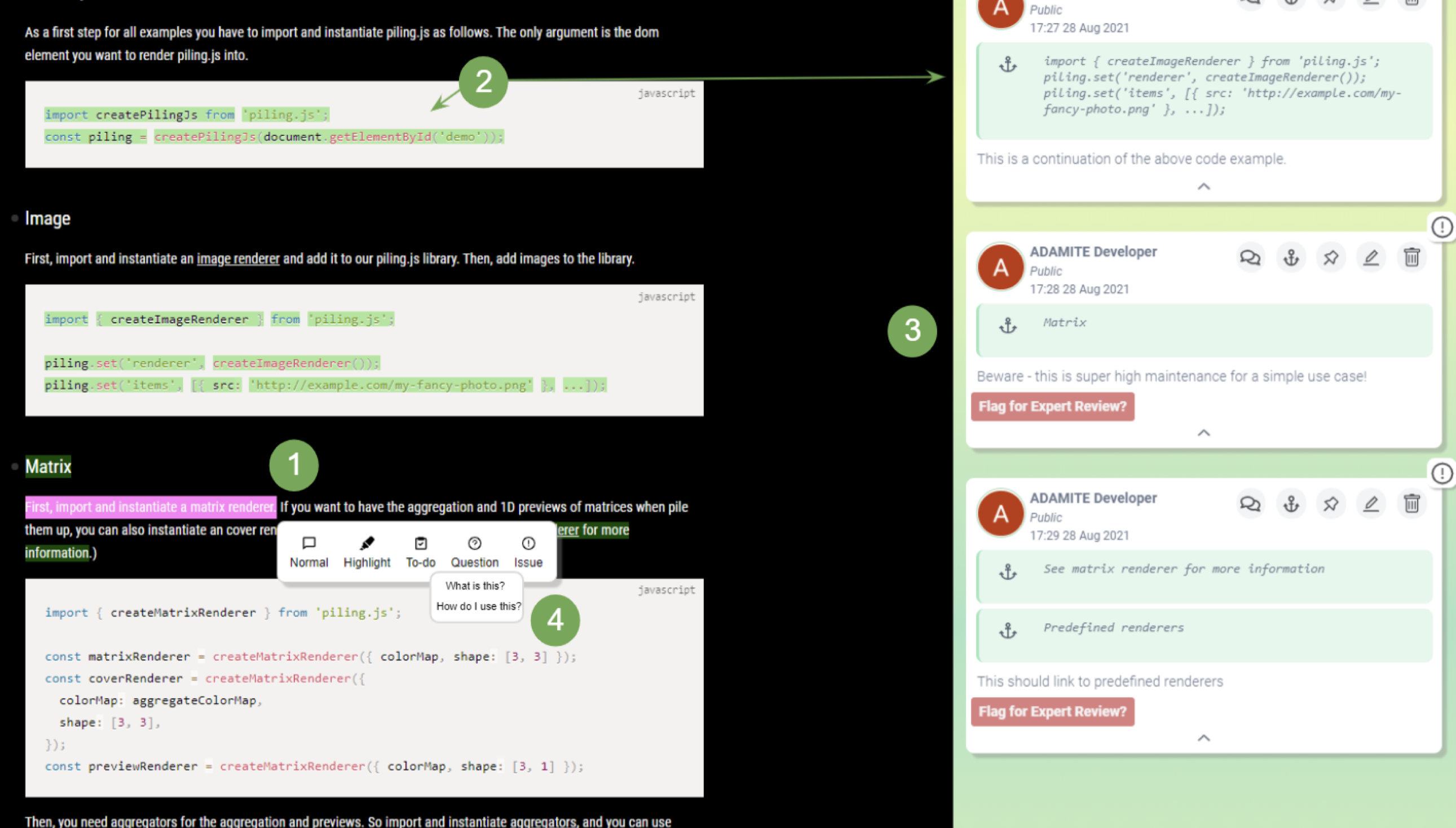
Our long paper UNAKITE: Support Developers for Capturing and Persisting Design Rationales When Solving Problems Using Web Resources is accepted to DTSHPS 2018. Check it out here.
- 7 years ago
Our poster An Exploratory Study of Web Foraging to Understand and Support Programming Decisions is accepted to VL/HCC 2018. Check it out here.
- 7 years ago
I re-wrote this website as a Single Page Application (SPA) with Gatsby.js and React.js! Way shorter loading time and better performance! It used to be based on Jekyll.
- 7 years ago
I presented our position paper Supporting Knowledge Acceleration for Programming from a Sensemaking Perspective at CHI 2018 Sensemaking Workshop. Check it out here.
- 7 years ago
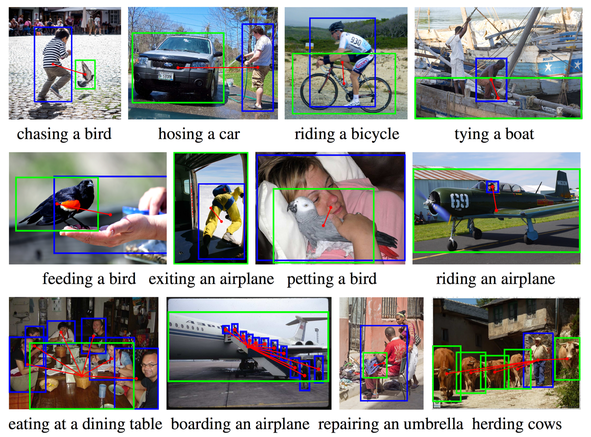
Our paper Learning to Detect Human-Object Interactions is accepted to WACV 2018. Check it out here.
- 7 years ago
Check out my Paper Reader app to support better reading experience of pdf documents (especially research papers) on mobile phones!
- 8 years ago
Dr. Brad A. Myers and Dr. Niki Kittur are my advisors here at CMU HCII.
- 8 years ago
I started as a Ph.D. student at Human-Computer Interaction Institute @ Carnegie Mellon University in August 2017!
- 8 years ago
I am deeply honored to receive my B.S. in Electrical and Computer Engineering from Shanghai Jiao Tong University in August 2017.
- 8 years ago
I am deeply honored to receive my B.S. in Computer Science from University of Michigan, Ann Arbor in April 2017.